Functional Foundations - Functions
When leveraging functional programming, you're not going to go far without functions. It's literally in the name.
In this post, let's take a deeper look at what functions are and some of the benefits we gain.
What is a Function?
When we talk about functions, we're not talking about a programming construct (like the function keyword), but instead we're talking about functions from mathematics.
As such, a function is a mapping from two sets such that for every element of the first set, it maps to a single element in the second set.
Words are cool, but pictures are better. So let's look at the mapping for the square function.
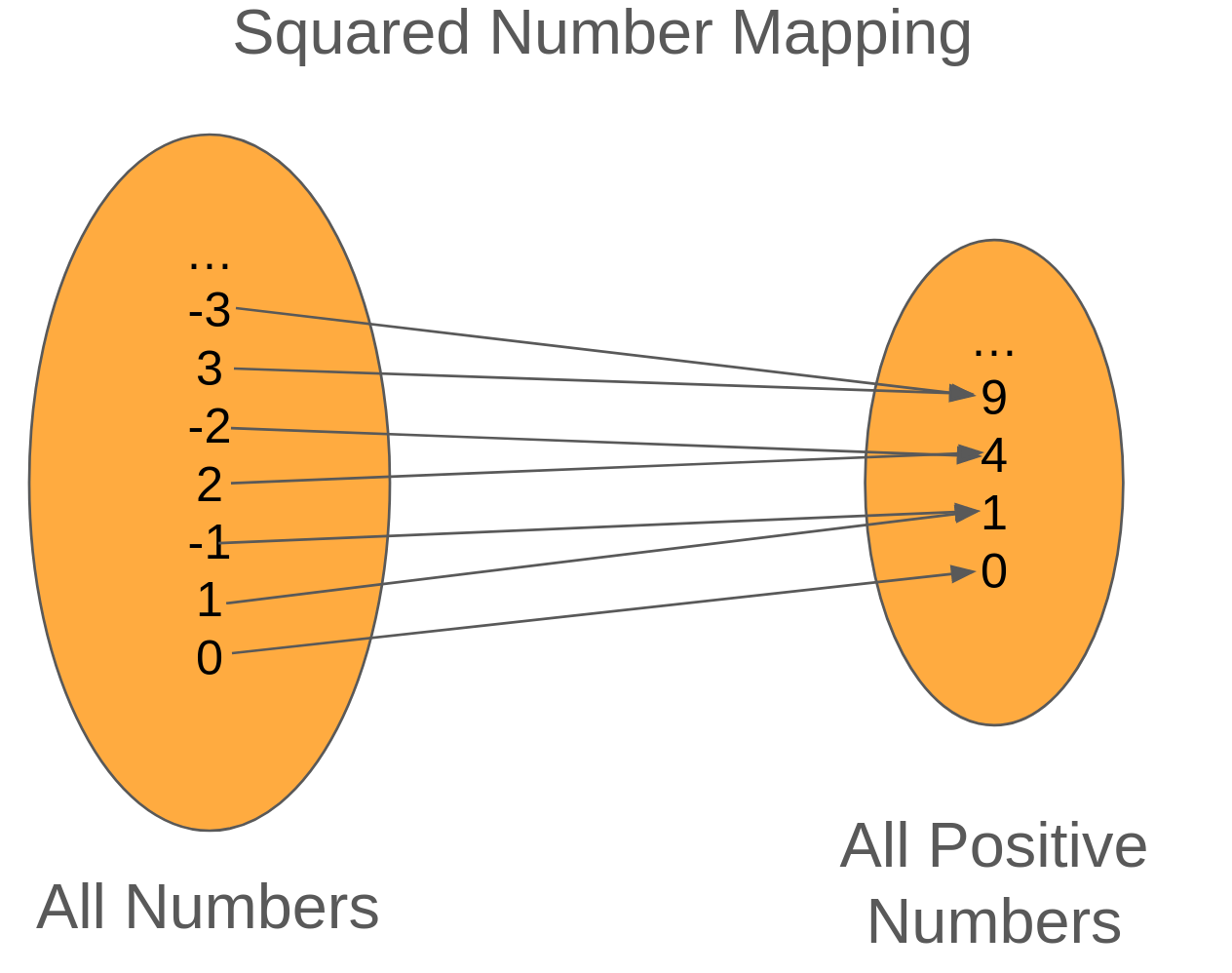
In this example, we have an arrow coming from an element on the left where it maps to an element on the right. To read this image, we have a mapping called Square that maps all possible numbers to the set of positive numbers. So -3 maps to 9 (-3-3), 2 maps to 4 (22), so on and so forth.
To check if our mapping is a function, we need to check that every element on the left is mapped to a single element on the right. If so, then we've got a function!
Sounds easy, right? Let's take a look at a mapping that isn't a function.
Love in the Air?
When working with dates, it's common to figure out how many days are in the month. Not only does this help with billable days, but it also makes sure that we don't try to send invoices on May 32nd.
So let's take a look at a mapping from month to the number of days it has.
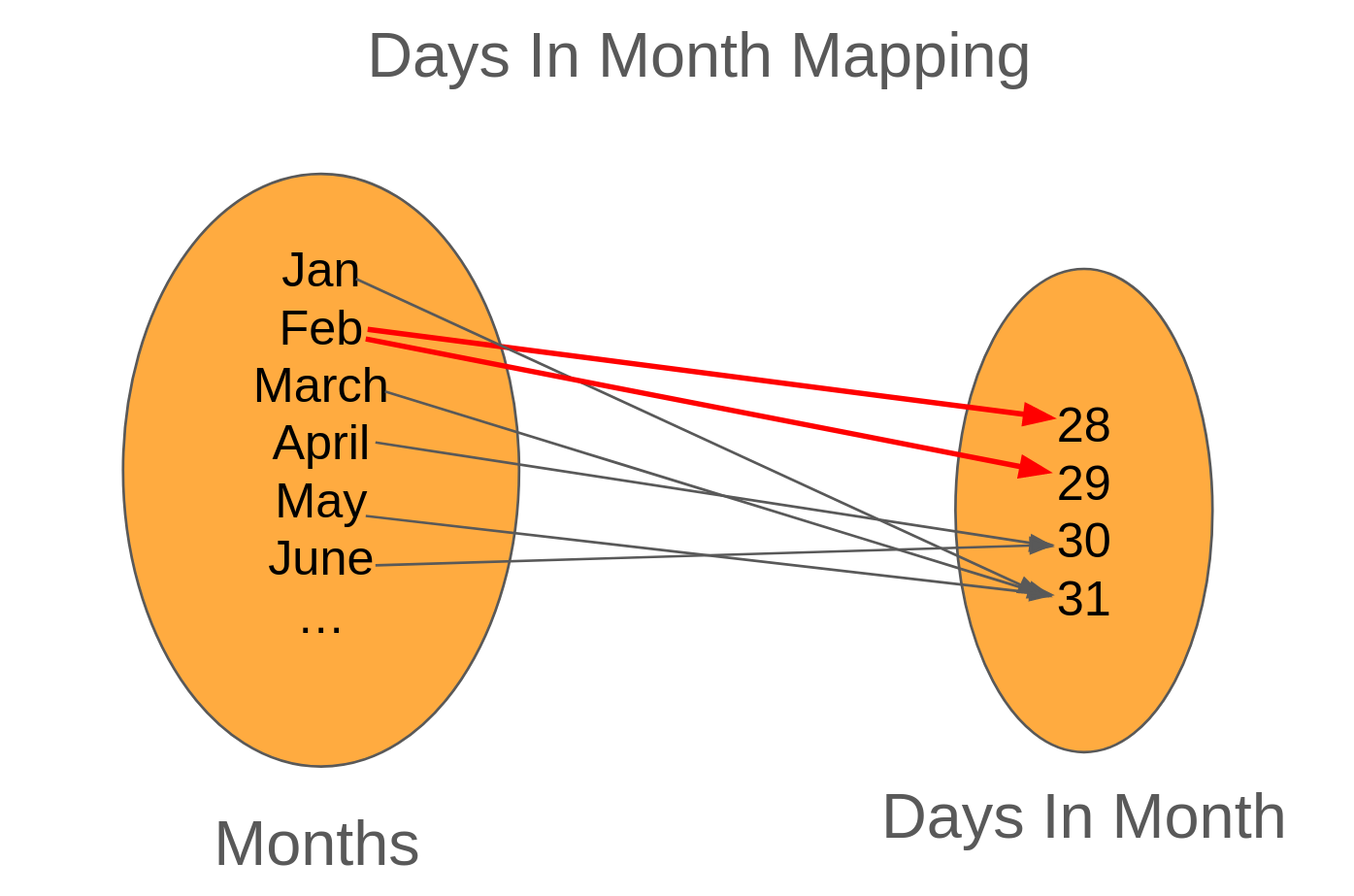
Looking at the mapping, we can tell that January, March, May map to 31, April and June both map to 30. But take a look at February. It's got two arrows coming out of it, one to 28 and the other to 29. Because there are two arrows coming out, this mapping isn't a function. Let's try to implement this mapping in TypeScript.
We can't return 28 all the time (we'd be wrong 25% of the time) and we can't return 29 all the time (as we'd be wrong 75% of the time). So how do we know? We need to know something about the year. One approach would be to check if the current year is a leap year (algorithm).
The problem with this approach is that the determination of what to return isn't from the function's inputs, but outside state (in this case, time). So while this "works", you can get bit when you have tests that start failing when the calendar flips over because it assumed that February always had 28 days.
If we look at the type signature of isLeapYear, we can see that it takes in no inputs, but returns a boolean. How can that be possible except if it always returned a constant value? This is a clue that isLeapYear is not a function.
The better approach is to change our mapping to instead of taking just a month name, it takes two arguments, a monthName and year.
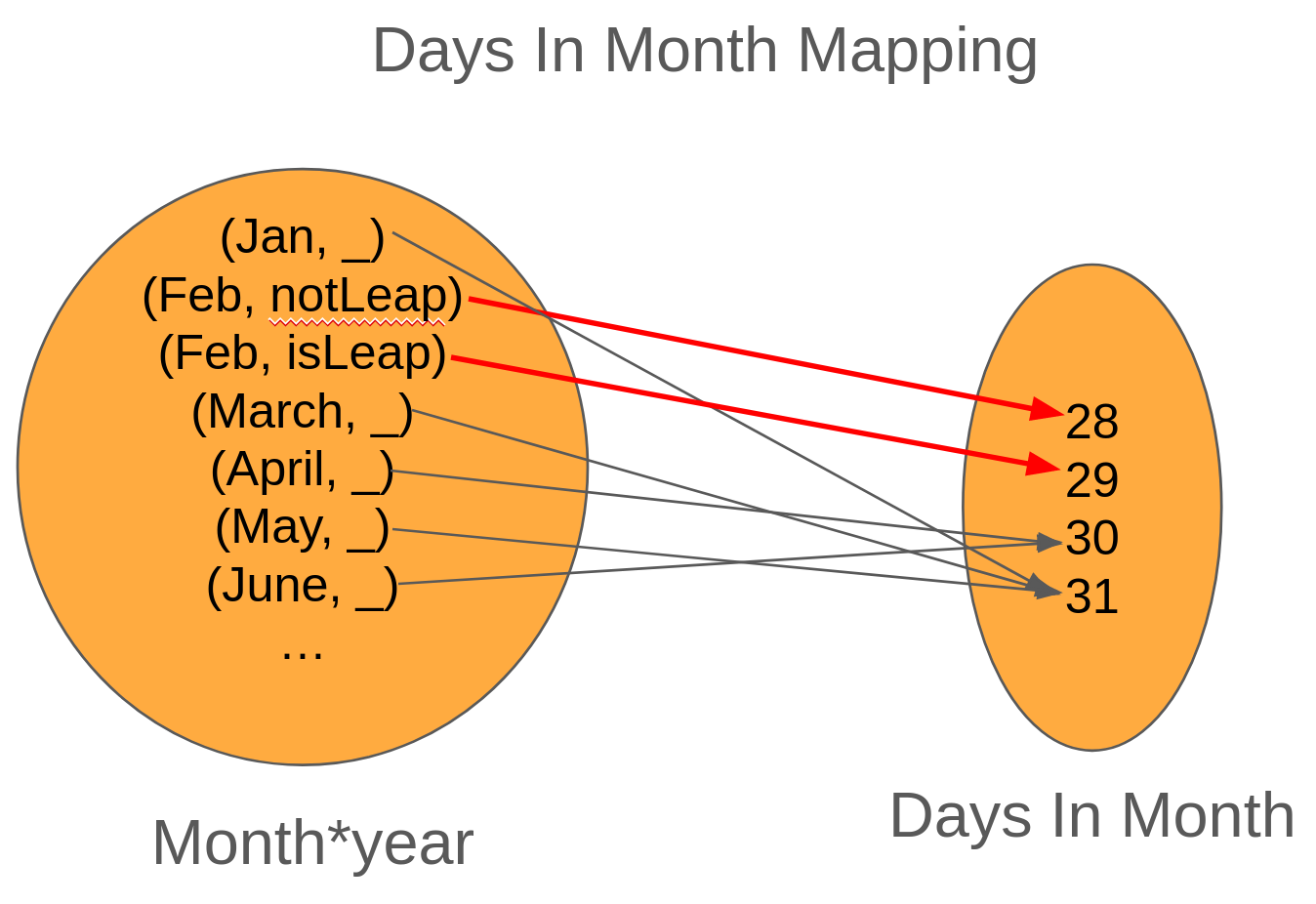
With this new mapping, our implementation would look like the following:
Benefits of Functions
Now that we've covered what functions are and aren't, let's cover some of the reasons why we prefer functions for our logic.
First, mappings help us make sure that we've covered all our bases. We saw in the getDaysInMonth function we found a bug for when the month was February. Mappings can also be great conversation tools with non-engineers as they're intuitive to understand and to explain.
Second, functions are simple to test. Since the result is based solely on inputs, they are great candidates for unit testing and require little to no mocking to write them. I don't know about you, but I like simple test cases that help us build confidence that our application is working as intended.
Third, we can combine functions to make bigger functions using composition. At a high level, composition says that if we have two functions f and g, we can write a new function, h which takes the output of f and feeds it as the input for g.
Sounds theoretical, but let's take a look at a real example.
In the Mars Rover kata, we end up building a basic console application that takes the input from the user (a string) and will need to convert it to the action that the rover takes.
In code, the logic looks like the following:
The annoying part is that we're iterating the list twice (once for each map call), and it'd be nice to get it down to a single iteration. This is where composition helps.
When we're running the maps back-to-back, we're accomplish the following workflow
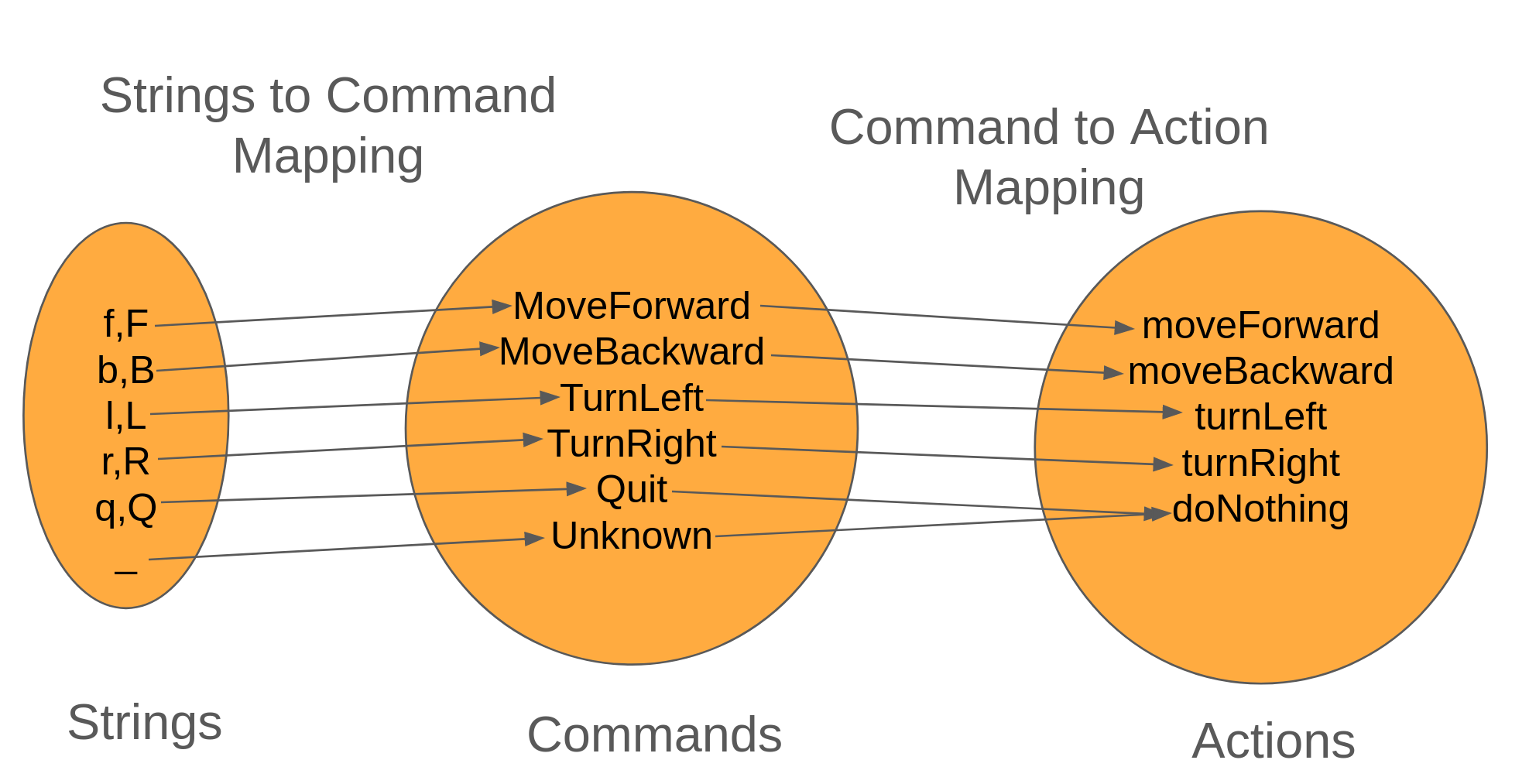
Because each mapping is a function, we can compose the two into a new function, stringToActionConverter.
Why Not Function All the Things?
Functions can greatly simplify our mental model as we don't have to keep track of state or other side effects. However, our applications typically deal with side affects (getting input from users, reading from files, interacting with databases) in order to do something useful. Because of this limitation, we strive to put all of our business rules into functions and keep the parts that interact with state as dumb as possible (that way we don't have to troubleshoot as much).
What I've found is that when working with applications, you end up with a workflow where you have input come in, gets processed, and then the result gets outputted.
Here's what an example workflow would look like
What's Next?
Now that we have a rough understanding of functions, we can start exploring what happens when things go wrong. For example, could there have been a cleaner way of implementing the business rules of our workflow?
