Testing Non Deterministic Code - Debugging Shuffle with Property Based Testing
Background
Now that I've gotten a handle on my work situation, I've been focusing my time to complete work on my upcoming Functional Blackjack course. I've gotten the business rules implemented so I've been playing some games to make sure everything is working the way I'd expect.
For example, here's what the UI looks like for when the game is dealt out.
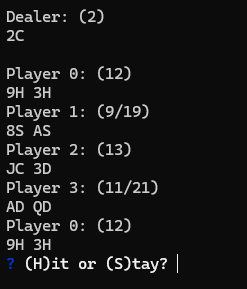
So far, so good. However, every now then, I'd see error messages like this one where I'd be trying to calculate the score of a null card.
![]()
Doing some digging, I discovered that when I was creating my player, they could have a null card!

What could be happening? I'm leveraging functional programming techniques (immutable data structures, pure functions for business rules). Given that it doesn't happen all the time, it must be in some of my side-effect code. Combine that thought with the fact the game would break upon start, I had an idea of what might be the cause.
Identifying Possible Problem
In order to create a player, we need to have an id (some arbitrary number) and two cards. These cards are coming from the deck, so let's take a deeper look at how that's being created.
So far, so good. the first section is building all possible combinations of Rank/Suit to model the deck. The only thing that is suspect is the shuffle function, so let's take a look at it.
Hmm, I don't see anything obviously wrong, however, I've got a hunch this is the problem because it's leveraging Math.random() which would explain why sometimes it works and sometimes it doesn't. Since Math.random() looks at the system clock, this isn't a pure function, so shuffle can't be a pure function (which makes sense, if shuffle always gave the same output for the same input, then we'd clean house, right :) )
My first instinct is to write some unit tests on this function. But how would you unit test shuffle? You could write a test case easily enough for an empty list and a list of one item, however, things get messy once you try to work around Math.random.
Let's try a different approach, using a property testing approach.
Verifying the Problem Using Property Based Testing
Instead of thinking in concrete terms (given this specific input, I should get this specific output), let's think about what properties a properly shuffled array would have.
- Should maintain length (i.e. if we shuffle an array of 10 elements, we should have 10 elements back)
- Should contain all original items (i.e. if we shuffle the numbers 1-10, then we shouldn't have an 11 or null in the array)
Implementing Maintains Length Property
Using the fast-check library, we can start modeling the first property:
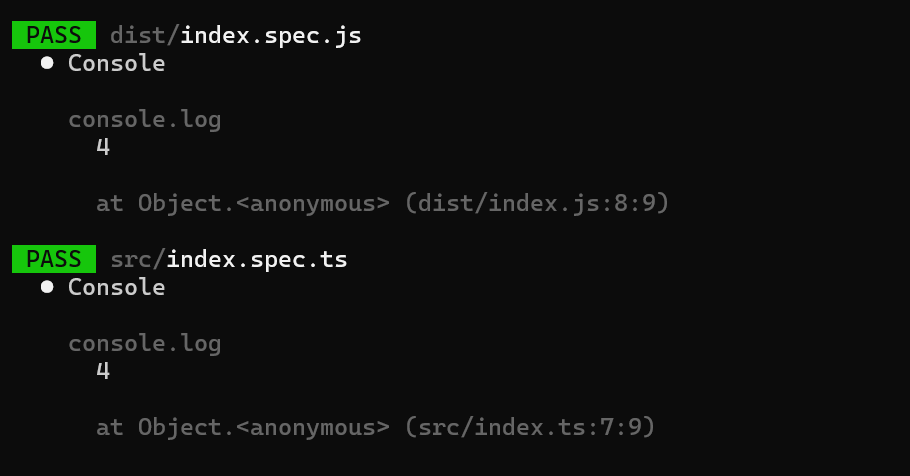
Seems simple enough, let's see what we get:
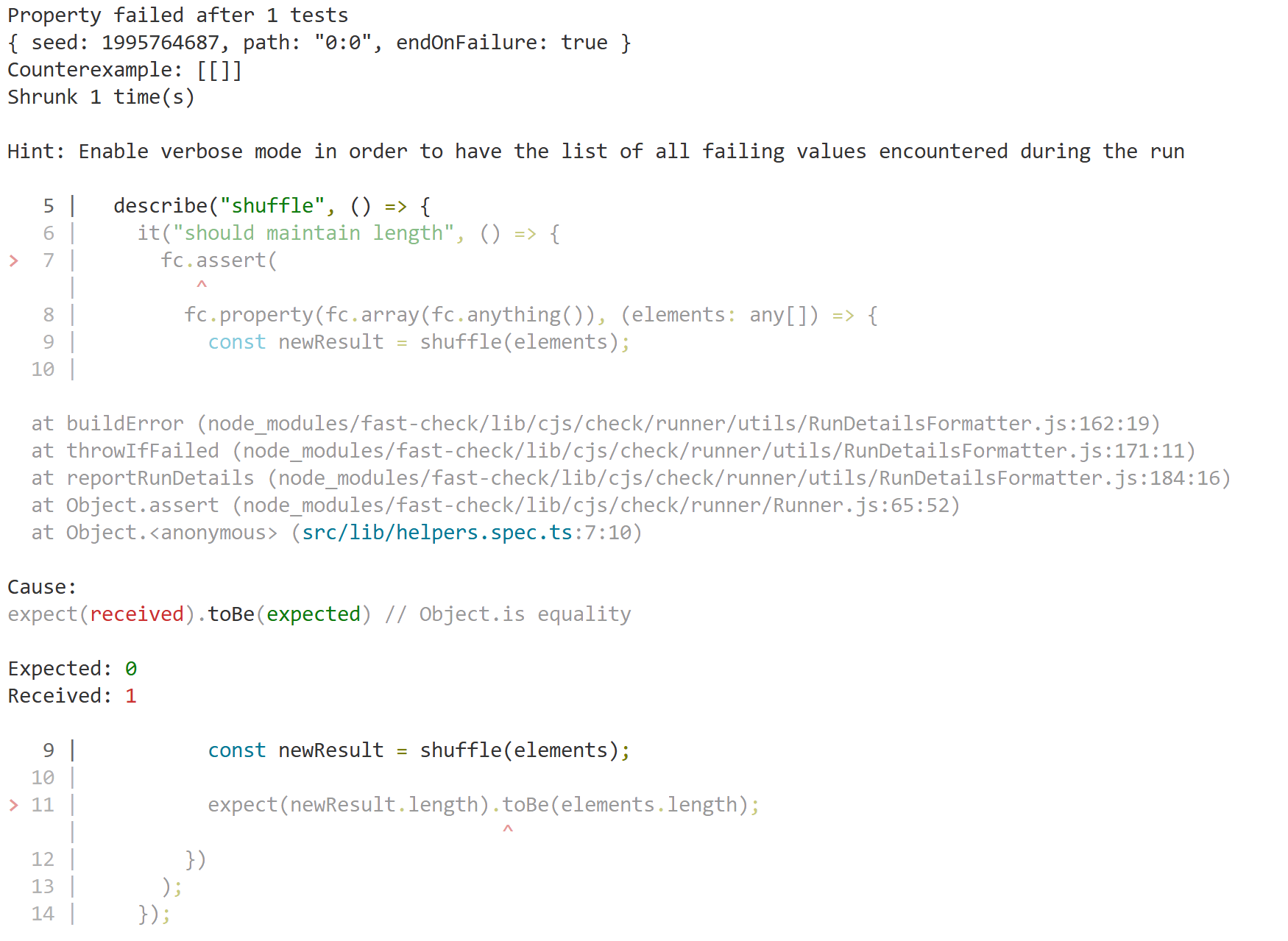
Whelp, that was easy enough, let's tweak our shuffle function to make that property pass:
Running the test suite again, we get a passing run, hooray!
Implementing Must Have All Original Items Property
With the first property written up, let's take a shot at writing the second property. For this test, we need to keep track of the original elements before they were shuffled up.
Next, we need to go through each element of result and remove it from the original array. If we find an item that can't be removed, we should fail the test. Otherwise, we can remove it from original.
Note: Astute readers might have noticed we're not asserting that the original array is empty after the for loop. Since we have the test that verifies that we're maintaining length, that check is not needed here.
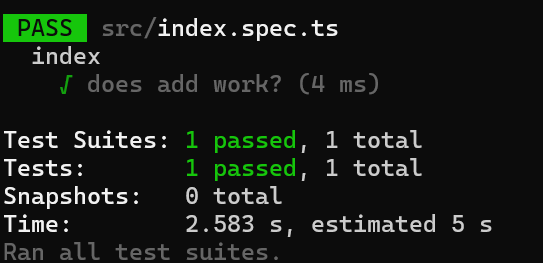
Running the test suite, it looks like everything is passing. So to make sure that our test would catch issues, let's inject a bug into the shuffle algorithm!
If we run the test now, we get the following:
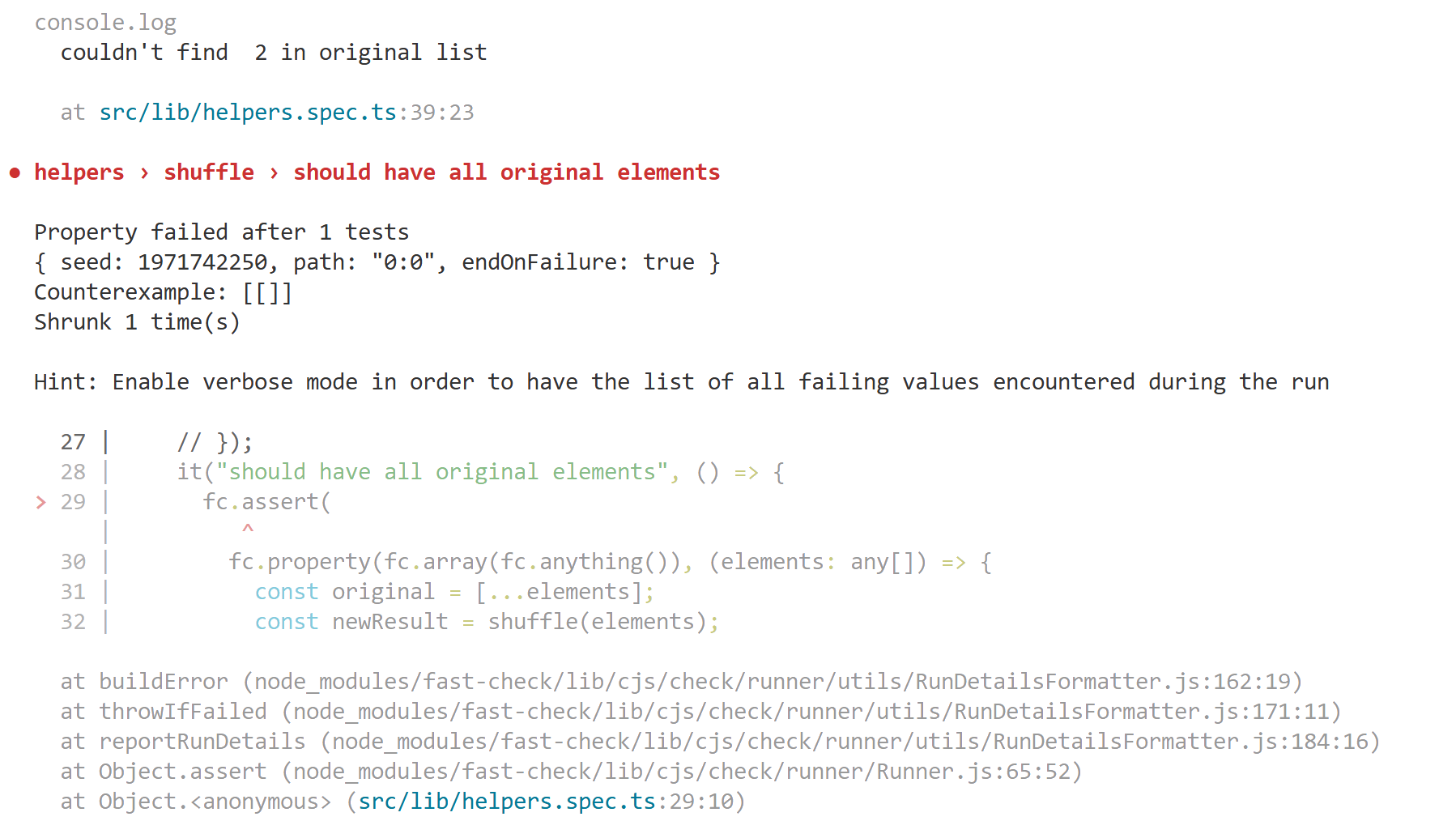
Based on the tests and the code change that we made, I'm feeling confident that my bug was found and has been solved.
Wrapping Up
In this post, we looked at an issue I was dealing with in my codebase (a mysterious introduction of null). From there, we were able to narrow down to a possible culprit, the shuffle function as it's not a pure function. Using fast check and property testing principals we were able to derive two properties that shuffle should follow and then encode that logic.
The next time you find yourself needing to write tests and are struggling with good inputs, try thinking about properties instead!