There's been a bit of a lull the past couple of weeks on the blog as I've been focusing my time on studying and preparing for the AZ-104 exam. This was a particularly challenging certificate for me as I don't have a traditional IT Admin background so I had to not only shore up the gaps in that knowledge, but then also had to learn how to model similar concepts in Azure.
That being said, I was able to pass the exam on my first take and wanted to share some advice for those who are looking to take this or other Azure exams.
The Microsoft Learn docs are fine for doing a deep dive into a subject, but if it's the first time learning a concept, then they can be a bit rough as they assume you have knowledge that you might not. To help round out your learning, I recommend finding other resources like videos, books, or articles.
Given that most of these concepts are pretty abstract, I found that they stuck with me much more when I build out the resources. For example, when working with a Virtual Machine, all of its components need to be in the same region. You can either remember that text OR you know that has to be true because if you try building out the VM in Azure and try to change components, it's going to fail.
Back in 2019, I was studying/preparing for the 483 (exam on C#) and the advice at the time was to go over the practice exams over and over again until things stuck. Following the same advice, I took tons of practice exams (through MS Learn and MeasureUp) and though they might have had the same format as the exam (multiple choice, drag-and-drop, etc...), none of them were a good stand-in for the real exam.
The reason being is that the exam questions likely won't ask you to define a term, but are more likely to be along the lines of how you'd solve a problem (which expects you to know the terminology inherently). So if you don't have the underlying knowledge, you're going to have a bad time trying to answer the questions.
Where the practice exams shone was helping me identify areas that I needed to focus more on. For example, if I struggled in the Networking section, then I know I needed to revisit concepts there. This helped me make the most of my studying time.
Given that I don't come from a networking/IT background, there were some concepts that were quite confusing to me. For example, I was trying to understand why I would need System routes if we already had Network Security Groups and Copilot was able to give me the following:
To help make sure I didn't fall victim to hallucinations, I followed up on the links that Copilot provided to make sure that I understood the concepts, but given that I learn best by asking questions, this was a major win for me since you can't ask questions to books/videos.
Recently, I was doing analysis for a project where we needed to build out a set of APIs for consumers to use. Even though I'm a big believer of iterative design, we wanted to have a solid idea of what the routes and data models were going to look like.
In the past, I most likely would have generated a .NET Web API project, created the controllers/models, finally leveraging NSwag to generate Swagger documentation for the api. Even though this approach works, it does take more time on the implementation side (spinning up controllers, configuring ASP.NET, creating the models, adding attributes). In addition, if the actual API isn't being written in with .NET, then this code becomes throwaway pretty quickly.
Since tooling is always evolving, I stumbled across another tool, TypeSpec. Heavily influenced by TypeScript, this allows you to write your contracts and models that, when compiled, produces an OpenAPI compliant spec.
Given that it's inspired by TypeScript, the tooling requires having Node installed (at least 20, but I'd recommend the long-term-supported (LTS) version).
From there, we can install the TypeSpec tooling with.
Even though this is all the tooling that's required, I'd recommend installing an extension for either Visual Studio or Visual Studio Code so that you can get Intellisense and other visual cues while you're writing the code.
So far, not much to look at. However, if we copy this code and render feed it to an online render (like https://editor.swagger.io/), we'll get a message about no operations.
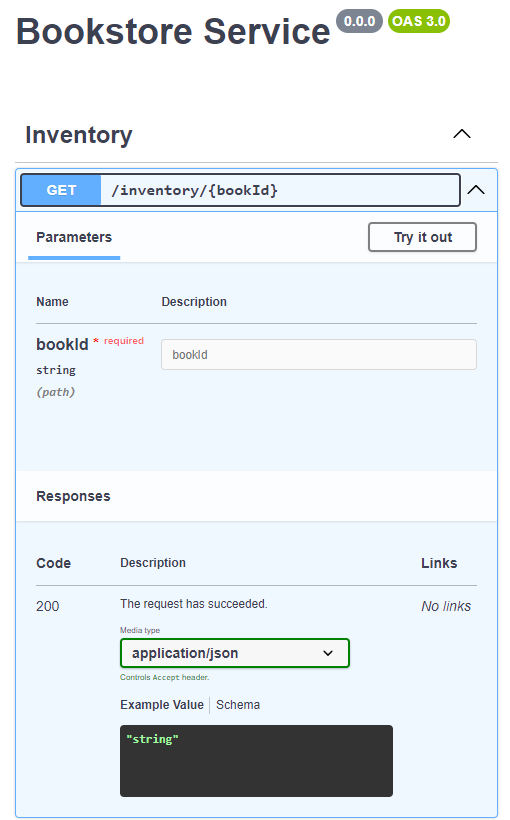
Let's change that by building out our GET endpoint.
Back in main.tsp, let's add more code to our Bookstore namespace.
namespace Bookstore {
// Note that we've added this to the Bookstore namespace
model Book {
id: string;
title: string;
@minValue(1)
price: decimal;
authorName: string;
}
@tag("Inventory")
@route("inventory")
namespace Inventory {
// For our get, we're now returning a Book, instead of a string.
@get op getBook(@path bookId: string): Book;
}
}
After another run of tsp compile and rendering the yaml file, we see that we have a schema for our get method now.
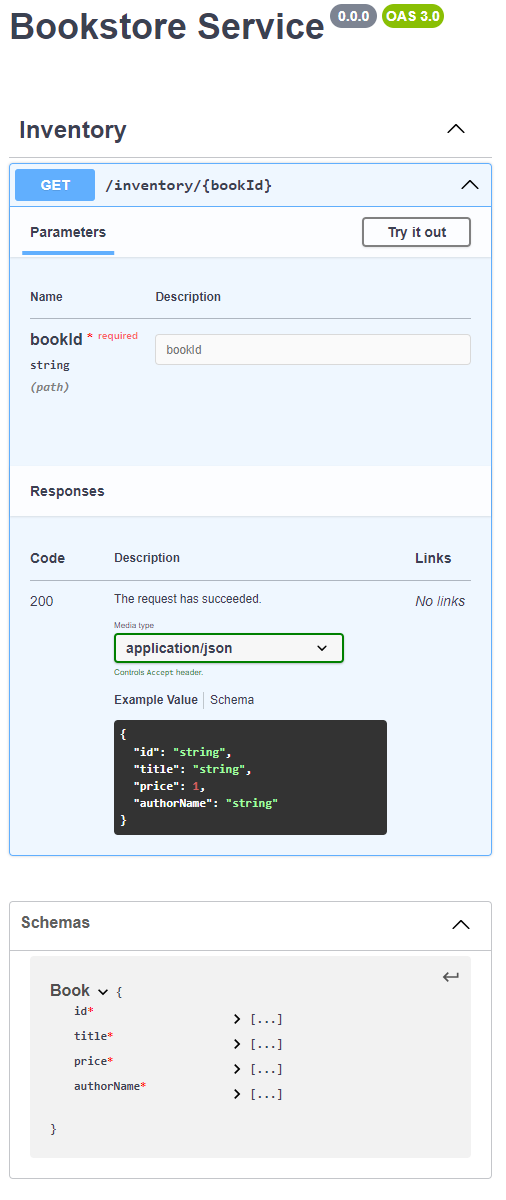
Even though this works, the Book model is a bit lazy as it has the authorName as a property instead of an Author model which would have name (and a bit more information). Let's update Book to have an Author property.
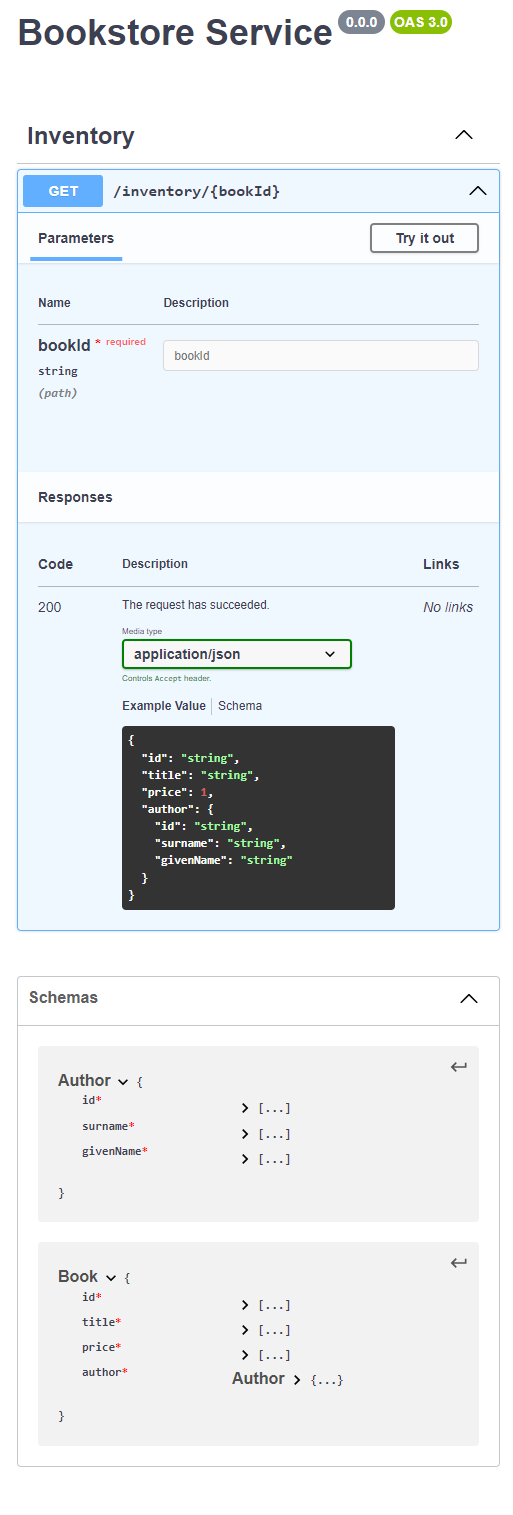
We're definitely a step in the right direction, however, our API definition isn't quite done. Right now, it says that we'll always return a 200 status code.
I don't know about you, but our bookstore isn't good enough to generate books with fictitious IDs, so we need to update our contract to say that it can also return 404s.
Back in main.tsp, we're going to change our return type of the @get operation to instead of being a Book, it's actually a union type.
@get op getBook(@path bookId: string):
// Either it returns a 200 with a body of Book
{
@statusCode statusCode: 200;
@body book: Book;
} | { // Or it will return a 404 with an empty body
@statusCode statusCode: 404;
};
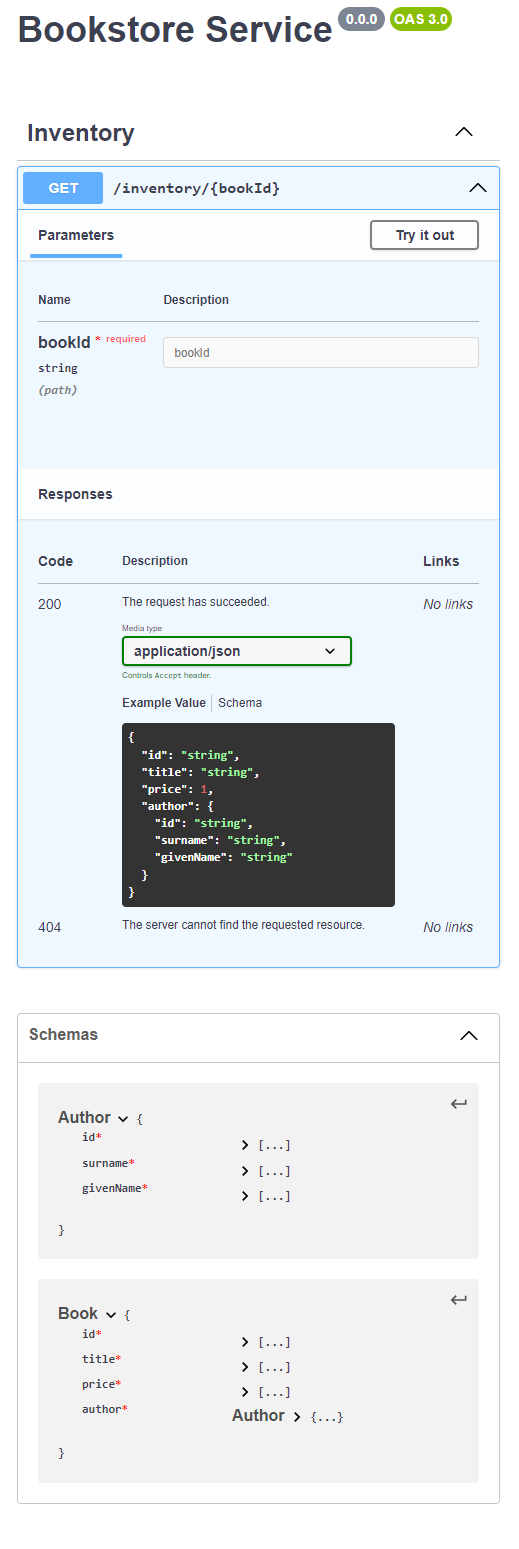
With this final change, we can compile and render the yaml and see that route can return a 404 as well.
When I first started with TypeSpec, my first thought was that you could put this code under continuous integration (CI) and have it produce the OpenAPI format as an artifact for other teams to pull in and auto-generate clients from.
There are few fundamental truths in life, one of which is that the only consistent thing is change. Whether that's through a reorganization, someone leaving the team, or the start of a new initiative, we know that what happens today is different from yesterday, and as a leader, the team is looking to you to figure out how to navigate these changes.
In this post, I'll share some tips and tricks for leading the team through change.
A common mistake I see leaders make is introducing a change without discussing why the change is happening. Let's look at a hypothetical situation where you're introducing the team to pull request templates.
Hey team! Starting next sprint, we're going to start using this new PR template. You can find it ....
On the one hand, the message is clear on what's changing (using new PR template). However, it completely missed the point, why are we making this change? When we don't include the why, we catch people off-guard because they may not immediately understand the problem that the change is supposed to solve.
When we put people in an information vacuum, they draw their own conclusions, which can give the wrong impression behind the change. This in turn, can cause the rumor mill to go into overdrive, making your job much harder.
Let's revisit the same scenario but include the "why" this time.
Hey team! During our last retro, it was brought up that our pull requests descriptions aren't consistent, which makes reviewing them more difficult. To help build consistency, we're going to start using pull request templates. You can find it ....
By making this small change, we can squash misinformation and potential rumor mills because we're clear on the reasoning.
When explaining the reason, don't lie or sugarcoat the reasoning, even if it makes you feel uncomfortable. Your team is smart and they'll know if you're lying to them.
A hot topic nowadays are Return to Office (RTO) plans, with a common reason being "need more in-person collaboration." Even though this provides a "why," it's not backed by metrics or anything measurable. In addition, in-person doesn't necessarily mean more collaboration.
A better approach is to use employee engagement surveys or customer satisfaction surveys to measure the effectiveness of team or company. If you can't use these metrics (or other relevant metrics), then why are you introducing this change?
Going back to our hypothetical RTO, let's say that the reason we're going back to the office is that we're a start-up whose investors have already paid for our space. To them, having people in the space helps them feel better that their money is well spent (in addition, some companies have a tax break if they moved to your state as long as they have a percentage of people on-site).
This is what you should be telling your team. They may not like the reason and they might disagree, but they know the why and then they can make their own decisions. Long story short, you're giving them the autonomy to make their own decisions because they have all the information.
Humans don't have perfect memories, right? So why would we expect that once we introduce a change that's the last time we need to talk about it?
Regardless of the change, don't be surprised if you need to mention it 3 or 4 times before people finally start understanding and applying the change. A great mentor of mine once told me that he would tell people about the change time and time again until it stuck. While this was happening, he would show patience, repeat the messaging, and answer questions and concerns.
When we hear of change, our first step is start processing the message and the immediate impacts. Some people will have questions immediately while others need time to stew on it.
Because of this, be available to answer questions as they come up (even if you've already answered them before). Be prepared for questions during one-on-ones, after meetings, or whenever they come up.
Acknowledge the questions and answer them. If you don't know the answer, tell them that you don't know and that you're going to find the answer.
Don't be surprised that your team exhibits a wide range of emotions for more significant changes.
For example, if your company is doing layoffs, then it's reasonable for people to be upset, depressed, or mentally checked out.
When this happens, you have to give people space to process. This doesn't mean isolating them but being aware that they need some time and accommodate accordingly.
A common mistake I see leaders make here is introducing a change, thinking it was low impact, so they start making other changes. In reality, this change had a high impact, and now the team is under pressure to handle the original change and whatever new commitments are coming their way.
Not only does this reduce your odds of success, but this prevents your team from dealing with the changes, which can turn into stress or frustration. If this happens enough times, people will change teams (or even jobs) just to get a change of scenery and be able to process.
Even though changes are going to happen, do not introduce one change this week, another next week, and then one more two weeks later.
As engineers, we learned that refactoring a codebase should be done in small steps to prevent functionality from breaking.
While this works great for code, this is terrible advice for humans.
When frequent changes happen, it becomes difficult to get into a rhythm with the work and the team, reducing the effectiveness of the team.
When we get changes happening like this, it becomes difficult to get into a rhythm with the work and the team. Especially if large changes keep happening every few weeks.
In the current landscape, we're seeing companies go through multiple rounds of layoffs. While this may keep them out of the news (no one reports that a company laid off ten people, even if it's the fourth time it's happened this year), it causes a feeling of dread for the survivors, as now they're thinking when they'll be next.
Instead of having multiple layoffs, if companies had one (albeit larger) layoff, this would allow people to have time to adjust and proceed without as much paranoia.
Validating input. You've got to do it, otherwise, you're going to be processing garbage, and that never goes well, right?
Whether it's through the front-end (via a form) or through the back-end (via an API call), it's important to make sure that the data we're processing is valid.
Coming from a C# background, I was used to ASP.NET Web Api's ability to create a class and then use the FromBody attribute for the appropriate route to ensure the data is good. By using this approach, ASP.NET will reject requests automatically that don't fit the data contract.
However, picking up JavaScript and TypeScript, that's not the case. At first, this surprised me because I figured that this would automatically happen when using libraries like Express or Nest.js. Thinking more about it, though, it shouldn't have surprised me. ASP.NET can catch those issues because it's a statically typed/ran language. JavaScript isn't and since TypeScript types are removed during the compilation phase, neither is statically typed at runtime.
When writing validations, I find zod to be a delightful library to leverage. There are a ton of useful built-in options, you can create your own validators (which you can then compose!) and you can infer models based off of your validations.
To demonstrate some of the cool things that you can do with Zod, let's pretend that we're building out a new POST endpoint for creating a new book. After talking to the business, we determine that the payload for a new book should look like this:
// A valid book will have the following// - A non-empty title// - A numeric price (can't be negative or zero)// - A genre from a list of possibilities (mystery, fantasy, history are examples, platypus would not be valid)// - An ISBN which must be in a particular format// - A valid author which must have a first name, a last name, and an optional middle name
Since Author will need to be an object, we'll use z.object to signify that. Right off the bat, this prevents a string, number, or other primitive types from being accepted.
AuthorSchema.safeParse("someString");// will result in a failureAuthorSchema.safeParse(42);// will result in a failureAuthorSchema.safeParse({});// will result in success!
This is a great start, but we know that Author has some required properties (like a first name), so let's implement that by using z.string()
AuthorSchema.safeParse({});// fails because no firstName propertyAuthorSchema.safeParse({firstName:42});// fails because firstName is not a stringAuthorSchema.safeParse({firstName:"Cameron"});// succeeds because firstName is present and a string
However, there's one problem with our validation. We would allow an empty firstName
Finally, we have a way to enforce that an author has a non-empty firstName!. Looking at the requirements, it seems like lastName is going to be similar, so let's update our AuthorSchema to include lastName.
Nice! We're almost done with Author, we need to implement middleName. Unlike the other properties, an author may not have a middle name. In this case, we're going to leverage the optional function from zod to signify that as so.
exportconstNonEmptyStringSchema=z.string().min(1);exportconstAuthorSchema=z.object({firstName:NonEmptyStringSchema,lastName:NonEmptyStringSchema,// This would read that middleName may or not may be present. // If it is, then it must be a string (could be empty)middleName:z.string().optional(),});
With the implementation of AuthorSchema, we can start working on the BookSchema.
We know that a book must have a non-empty title, so let's add that to our definition. Since it's a string that must have at least one character, we can reuse the NonEmptyStringSchema definition from before.
With title in place, let's leave the string theory alone for a bit and look at numbers. In order for the bookstore to function, we've got sell books for some price. Let's use z.number() and add a price property.
This works, however, z.number() will accept any number, which includes numbers like 0 and -5. While those values would be great for the customer, we can't run our business that way. So let's update our price to only include positive numbers, which can be accomplished by leveraging the positive function.
Up to this point, all of our properties have been straightforward (simple strings and numbers). However, with genre, things get more complicated because it can only be one of a particular set of values. Thankfully, we can define a GenreSchema by using z.enum() like so.
Last, let's take a look at implementing the isbn property. This is interesting because ISBNs can be in one of two shapes: ISBN-10 (for books pre-2007) and ISBN-13 (all other books).
To make this problem easier, let's focus on the ISBN-10 format for now. A valid value will be in the form of #-###-#####-# (where # is a number). Now, you can take this a whole lot further, but we'll keep on the format.
Now, even though zod has built-in validators for emails, ips, and urls, there's not a built-in one for ISBNs. In these cases, we can use .refine to add our logic. But this is a good use case for a basic regular expression. Using regex101 as a guide, we end up with the following expression and schema for the ISBN.
When modeling types in TypeScript, I'd like to be able to do something like the following as this makes it clear that an ISBN can in one of these two shapes.
Lastly, one of the cooler functions that zod supports is infer where if you pass it a schema, it can build out a type for you to use in your application.
exportconstBookSchema=z.object({author:AuthorSchema,title:NonEmptyStringSchema,price:z.number().positive(),genre:GenreSchemaisbn:IsbnSchema});// TypeScript knows that Book must have an author (which has a firstName, lastName, and maybe a middleName)// a title (string), a price (number), a genre (string), and an isbn (string).exporttypeBook=z.infer<typeofBookSchema>;
describe('when validating a book',()=>{it("and the author is missing, then it's not valid",()=>{constinput={title:"best book",price:200,genre:"History",isbn:"1-23-456789-0"}constresult=BookSchema.safeParse(input);expect(result.success).toBe(false);});it("and all the fields are valid, then the book is valid",()=>{constinput={title:"best book",price:200,genre:"History",isbn:"1-23-456789-0",author:{firstName:"Super",middleName:"Cool",lastName:"Author"}};constresult=BookSchema.safeParse(input);expect(result.success).toBe(true);constbook:Book=result.dataasBook;// now we can start using properties from bookexpect(book.title).toBe("best book");});});
Welcome to Cameron's Coaching Corner, where we answer questions from readers about leadership, career, and software engineering.
In this post, we'll look at a question from TheRefsAlwaysWin about how to get a new engineer on their team to open up and get comfortable asking for help.
I've got a newish member to the team and they're still early in their career. They've got a good head on their shoulders, however, they tend to go down rabbit holes when problem solving and they don't speak up or ask for help.
They've asked me a few times about "how did I know ....", and a lot of the times, it's experience (I've been doing this for a few decades now).
How do I help them open up and ask more questions to the team and group?
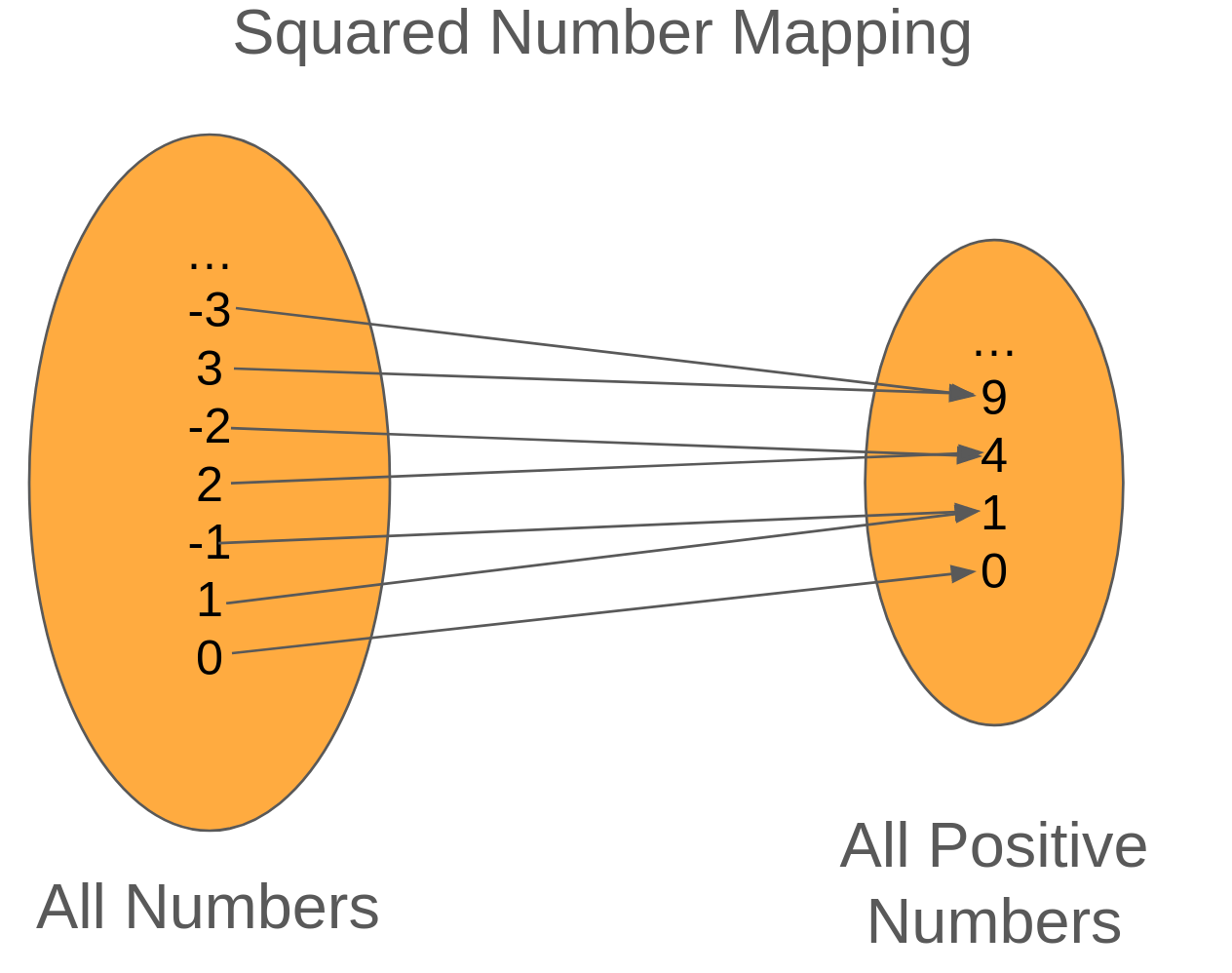
When we talk about functions, we're not talking about a programming construct (like the function keyword), but instead we're talking about functions from mathematics.
As such, a function is a mapping from two sets such that for every element of the first set, it maps to a single element in the second set.
Words are cool, but pictures are better. So let's look at the mapping for the square function.
In this example, we have an arrow coming from an element on the left where it maps to an element on the right. To read this image, we have a mapping called Square that maps all possible numbers to the set of positive numbers. So -3 maps to 9 (-3-3), 2 maps to 4 (22), so on and so forth.
To check if our mapping is a function, we need to check that every element on the left is mapped to a single element on the right. If so, then we've got a function!
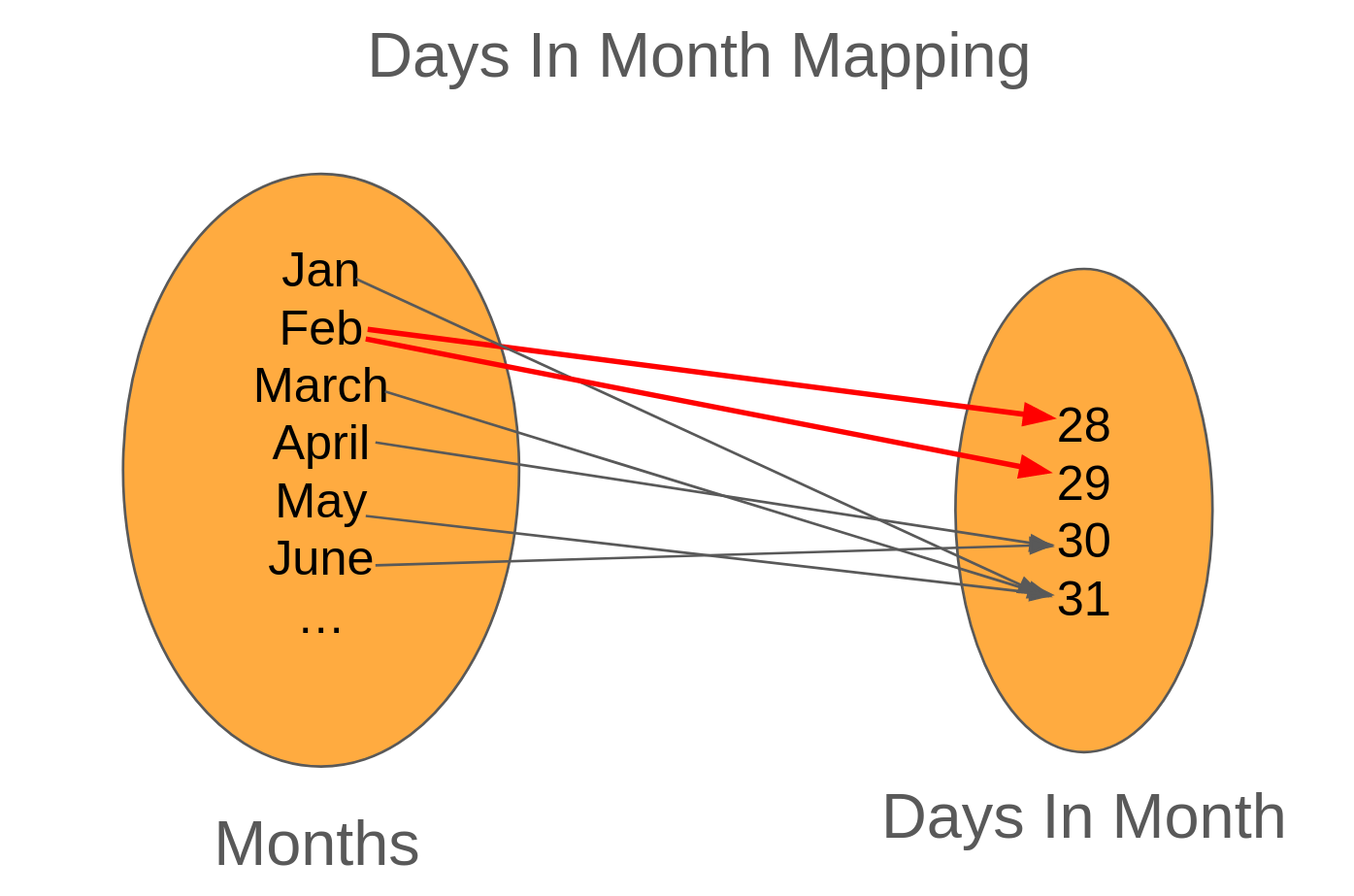
Sounds easy, right? Let's take a look at a mapping that isn't a function.
When working with dates, it's common to figure out how many days are in the month. Not only does this help with billable days, but it also makes sure that we don't try to send invoices on May 32nd.
So let's take a look at a mapping from month to the number of days it has.
Looking at the mapping, we can tell that January, March, May map to 31, April and June both map to 30. But take a look at February. It's got two arrows coming out of it, one to 28 and the other to 29. Because there are two arrows coming out, this mapping isn't a function. Let's try to implement this mapping in TypeScript.
typeMonth="Jan"|"Feb"|"Mar"|"Apr"|"May"|"Jun"|"Jul"|"Aug"|"Sept"|"Oct"|"Nov"|"Dec";typeDaysInMonth=28|29|30|31;functiongetDaysInMonth(month:Month):DaysInMonth{switch(month){case"Jan":case"Mar":case"May":case"Jul":case"Oct":case"Dec":return31;case"Feb":// what should this be?case"Apr":case"Jun":case"Aug":case"Sept":case"Nov":return30;}}
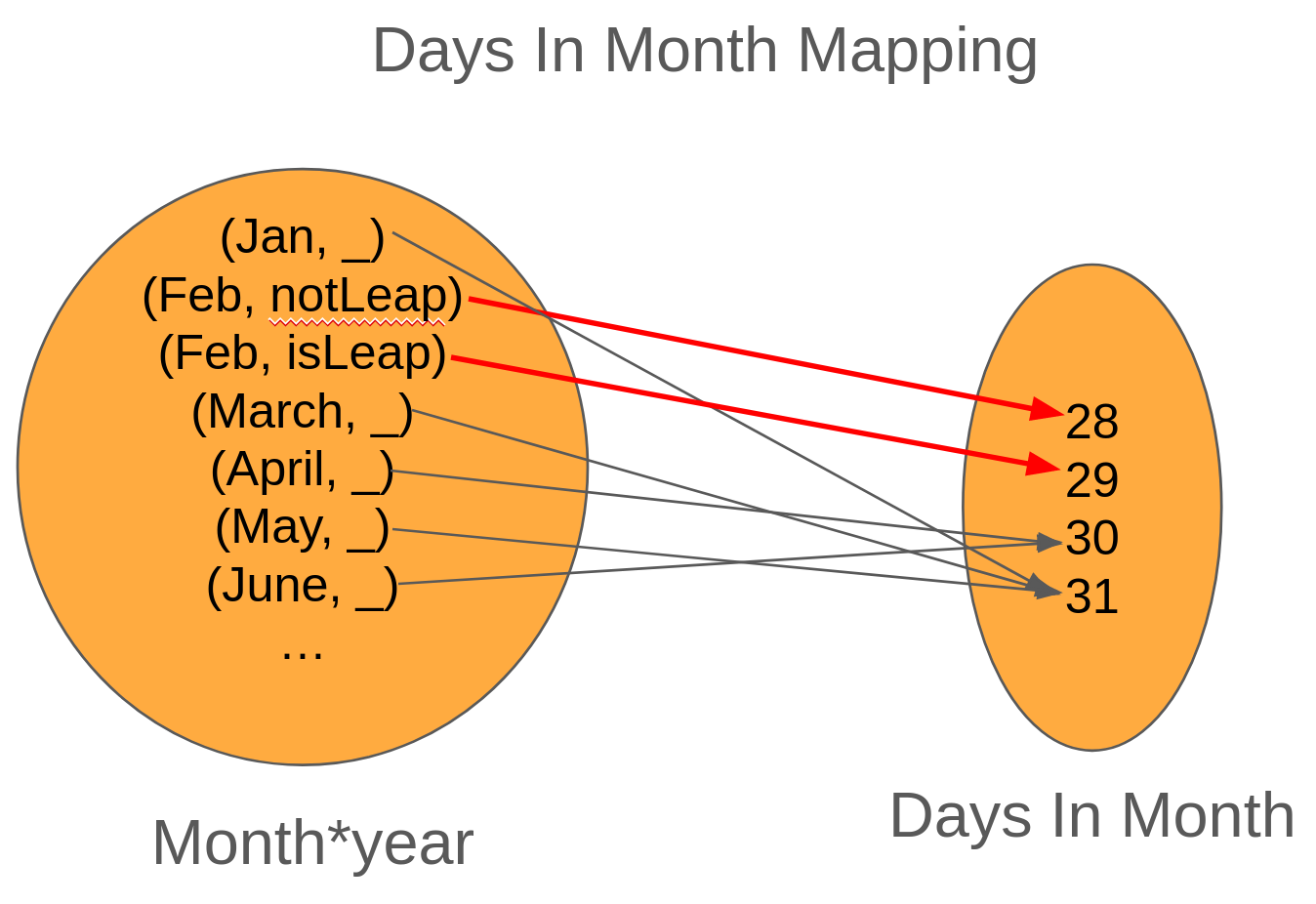
We can't return 28 all the time (we'd be wrong 25% of the time) and we can't return 29 all the time (as we'd be wrong 75% of the time). So how do we know? We need to know something about the year. One approach would be to check if the current year is a leap year (algorithm).
The problem with this approach is that the determination of what to return isn't from the function's inputs, but outside state (in this case, time). So while this "works", you can get bit when you have tests that start failing when the calendar flips over because it assumed that February always had 28 days.
If we look at the type signature of isLeapYear, we can see that it takes in no inputs, but returns a boolean. How can that be possible except if it always returned a constant value? This is a clue that isLeapYear is not a function.
The better approach is to change our mapping to instead of taking just a month name, it takes two arguments, a monthName and year.
With this new mapping, our implementation would look like the following:
Now that we've covered what functions are and aren't, let's cover some of the reasons why we prefer functions for our logic.
First, mappings help us make sure that we've covered all our bases. We saw in the getDaysInMonth function we found a bug for when the month was February. Mappings can also be great conversation tools with non-engineers as they're intuitive to understand and to explain.
Second, functions are simple to test. Since the result is based solely on inputs, they are great candidates for unit testing and require little to no mocking to write them. I don't know about you, but I like simple test cases that help us build confidence that our application is working as intended.
Third, we can combine functions to make bigger functions using composition. At a high level, composition says that if we have two functions f and g, we can write a new function, h which takes the output of f and feeds it as the input for g.
Sounds theoretical, but let's take a look at a real example.
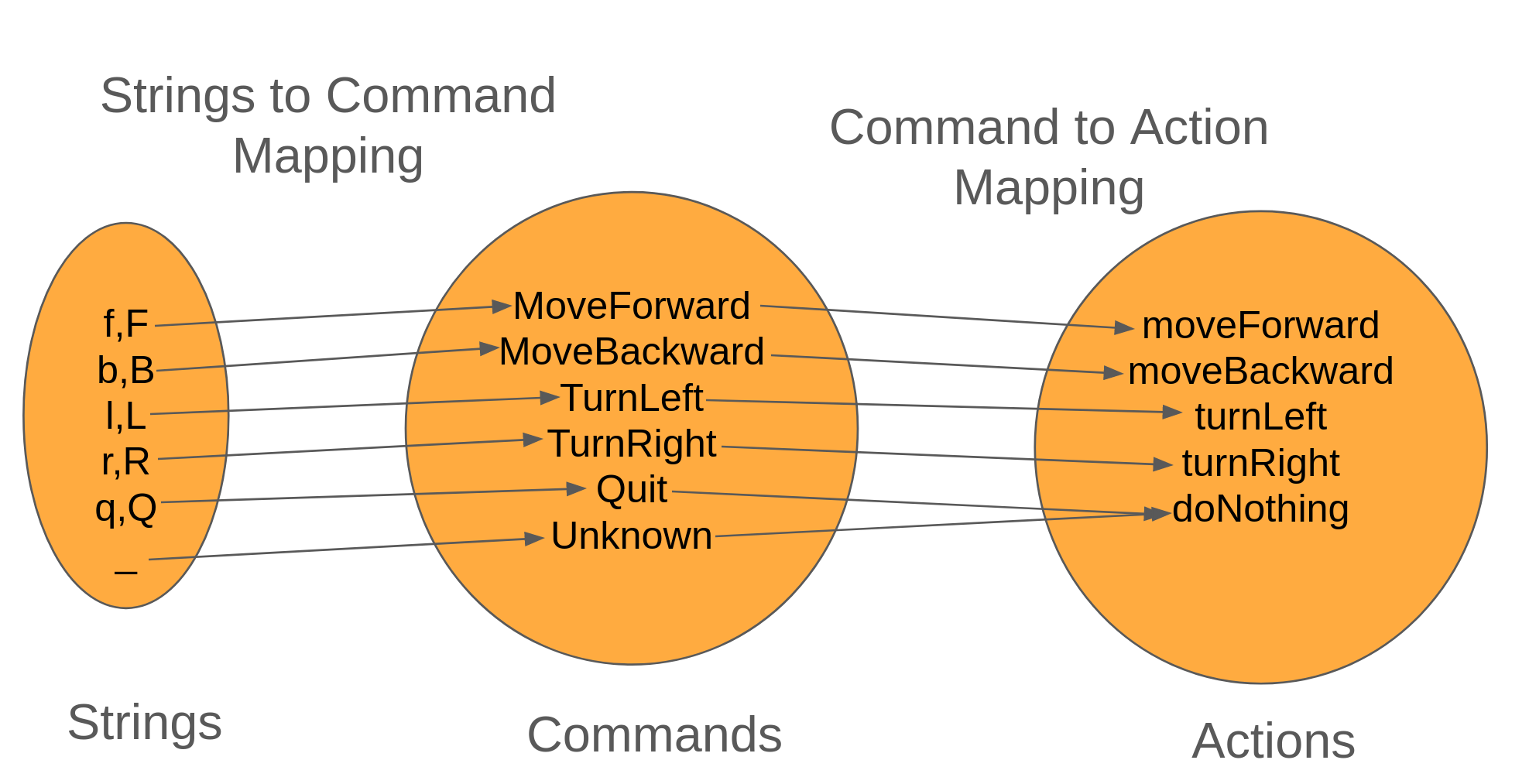
In the Mars Rover kata, we end up building a basic console application that takes the input from the user (a string) and will need to convert it to the action that the rover takes.
The annoying part is that we're iterating the list twice (once for each map call), and it'd be nice to get it down to a single iteration. This is where composition helps.
When we're running the maps back-to-back, we're accomplish the following workflow
Because each mapping is a function, we can compose the two into a new function, stringToActionConverter.
// using our f and g naming from earlier, convertString is f, convertCommand is gconststringToActionConverter=(s:string)=>convertCommandToAction(convertStringToCommand(s));letrover={x:0,y:0,direction:'North'}constaction=input.split('').map(stringToActionConverter);rover=action(rover);
Functions can greatly simplify our mental model as we don't have to keep track of state or other side effects. However, our applications typically deal with side affects (getting input from users, reading from files, interacting with databases) in order to do something useful. Because of this limitation, we strive to put all of our business rules into functions and keep the parts that interact with state as dumb as possible (that way we don't have to troubleshoot as much).
What I've found is that when working with applications, you end up with a workflow where you have input come in, gets processed, and then the result gets outputted.
// Logic to determine the 'FizzBuzziness' of a numberfunctiondetermineFizzBuzz(input:number):string{if(input%15===0)return'FizzBuzz';if(input%3===0)return'Fizz';if(input%5===0)return'Buzz';return`${input}`;}functionworkflow():void{// Input Boundaryvarprompt=require('prompt-sync')();constinput=prompt();// Business Rulesconstresult=(+input)?`${input} FizzBuzz value is ${determineFizzBuzz(+input)}`:`Invalid input`;// Output boundaryconsole.log(result);}
Now that we have a rough understanding of functions, we can start exploring what happens when things go wrong. For example, could there have been a cleaner way of implementing the business rules of our workflow?
I've recently found myself picking up C# again for a project and even though much of my knowledge applies, I recently found the following and it took me a minute to figure out what's up.
Let's say that we're working on the Mars Rover kata and we've decided to model the Rover type as a class with three fields: x, y, and direction.
My normal approach to this problem would have been the following:
publicenumDirection{North,South,East,West}publicclassRover{privateint_x;privateint_y;privateDirection_direction;publicRover(intx,inty,Directiondirection){_x=x;_y=y;_direction=Direction;}publicvoidPrint(){Console.WriteLine($"Rover is at ({_x}, {_y}) facing {_direction}");}}// Example usagevarrover=newRover(10,20,Direction.North);rover.Print();// Rover is at (10, 20) facing North
However, in the code I was working with, I saw the Rover definition as this
// note the params at the class line herepublicclassRover(intx,inty,Directiondirection){publicvoidPrint(){Console.WriteLine($"Rover is at ({x}, {y}) facing {direction}");}}// Example Usagevarrover=newRover(10,20,Direction.North);rover.Print();// Rover is at (10, 20) facing North
At first, I thought this was similar to the record syntax for holding onto data
And it turns out, that it is! This feature is known as a primary constructor and when used with classes, it gives you some flexibility on how you want to access those inputs.
For example, in our second implementation of Rover, we're directly using x, y, and direction in the Print method.
However, let's say that we didn't want to use those properties directly (or if we need to set some state based on those inputs), then we could do the following.
publicclassRover(intx,inty,Directiondirection){privatereadonlybool_isFacingRightDirection=direction==Direction.North;publicvoidPrint(){if(_isFacingRightDirection){Console.WriteLine("Rover is facing the correct direction!");}Console.WriteLine($"Rover is at ({x}, {y}) facing {direction}");}}
After playing around this for a bit, I can see how this feature would be beneficial for classes that only store their constructor arguments for later usage.
Even though Records accomplish that better, you can't attach functionality to Records, but you can with classes, so it does provide better organization from that front.
That being said, I'm not 100% sure why we needed to add the primary constructor feature to the language as this now opens up multiple ways of setting up constructors. I'm all for giving developers choices, but this seems ripe for bike shedding where teams have to decide which approach to stick with.
When modeling types, one thing to keep in mind is to not leverage primitive types for your domain. This comes up when we use a primitive type (like a string) to represent core domain concepts (like a Social Security Number or a Phone Number).
Here's an example where it can become problematic:
// Definition for CustomertypeCustomer={firstName:string,lastName:string,email:string,phoneNumber:string}// Function to send an email to customer about a new saleasyncfunctionsendEmailToCustomer(c:Customer):Promise<void>{constcontent="Look at these deals!";// Uh oh, we're trying to send an email to a phone number...awaitsendEmail(c.phoneNumber,content);}asyncfunctionsendEmail(email:string,content:string):Promise<void>{// logic to send email}
There's a bug in this code, where we're trying to send an email to a phone number. Unfortunately, this code type checks and compiles, so we have to lean on other techniques (automated testing or code reviews) to discover the bug.
Since it's better to find issues earlier in the process, we can make this a compilation error by introducing a new type for Email since not all strings should be treated equally.
One approach we can do is to create a tagged union like the following:
functionsendEmail(email:Email,content:string):Promise<void>{// logic to send email}
Now, when we get a compilation error when we try passing in a phoneNumber.
One downside to this approach is that if you want to get the value from the Email type, you need to access it's value property. This can be a bit hard to read and keep track of.
One technique to avoid this is to use destructuring to get the individual properties. This allows us to "throw away" some properties and hold onto the ones we care about. For example, let's say that we wanted only the phoneNumber from a Customer. We could get that with an assignment like the following:
constcustomer:Customer={firstName:"Cameron",lastName:"Presley",phoneNumber:"555-5555",email:{label:"Email",value:"Cameron@domain.com"}}const{phoneNumber}=customer;// phoneNumber will be "555-555"
This works fine for assignments, but it'd be nice to have this at a function level. Thankfully, we can do that like so:
// value is the property from Email, we don't have the label to deal withfunctionsendEmail({value}:Email,content:string):Promise<void>{constaddress=value;// note that we don't have to do .value here// logic to send email}
If you find yourself using domain types like this, then this is a handy tool to have in your toolbox.
As someone who enjoys leveraging technology and teaching, I'm always interested in ways to simplify the teaching process.
For example, when I'm teaching someone a new skill, I follow the "show one, do one, lead one" approach and my tool of choice for the longest time was LiveShare by Microsoft.
I think this extension is pretty slick as it allows you to have multiple collaborators, the latency is quite low, and it's built into both Visual Studio Code (VS Code) and Visual Studio.
First, participants have to be using Visual Studio or VS Code. Since there's support for VS Code, this isn't quite a blocker as it could be. However, let's say that I'm wanting to work with a team on a Java application. They're more likely to be using IntelliJ or Eclipse as their editor and I don't want someone to have to change their editor just to collaborate.
Second, there are some security considerations to be aware of.
Given the nature of LiveShare, collaborators either connect to your machine (peer-to-peer) or they go through a relay in Azure. Companies that are sensitive to where traffic is routed to won't allow the Azure relay option and given the issues with the URL creation (see next section), the peer-to-peer connection isn't much better.
To start a session, LiveShare generates a URL that the owner would share with their collaborators. As of today, there's no way to limit who can access that link. The owner has some moderator tools to block people, but there's not a way to stop anyone from joining who doesn't have the right kind of email address for example.
While pairing with a colleague, he introduced me to an alternative tool, mob.sh
At first, I was a bit skeptical of this tooling as I enjoyed the ease of use that I got with LiveShare. However, after a few sessions, I find that this tool solves the problems that I was using LiveShare for just as good, if not better.
At a high level, mob.sh is a command line tool that is a wrapper around basic git commands.
Because of this design choice, it doesn't matter what editor that a participant has, as long as the code under question is under git source control, the tooling works.
Let's explore how a pair, Adam and Brittany, would use this tool for work.
gitswitch-cfixing-logic-issue
mobstart--create
# --create is needed because fixing-logic issue is not on the server yet
Under the hood, mob.sh has created a new branch off of fixing-logic-issue called mob/fixing-logic-issue. While Adam is making changes, they're going to occur on the mob/fixing-logic-issue.
Because the pair is working remotely, Adam shares his screen so that they're on the same page.
While on this branch, Adam writes a failing unit test that exposes the logic issue that he's running into. From here he signals that Brittany is up by running mob next
By running this command, mob.sh adds and commits all the changes made on this branch and pushes them up to the server. Once this command completes, it's Brittany's turn to lead.
Once Brittany see's the mob next command complete, she checks out the fixing-logic-issue branch and picks up the next portion of the work by running mob start
gitpull# To get fixing-logic-issue branchgitswitchfixing-logic-issue
mobstart
Because she was on the fixing-logic-issue branch, mob.sh was able to see that there was a mob/fixing-logic-issue branch already, so that branch is checked out.
Based on the test, Brittany shows Adam where the failure is occurring and they write up a fix that passes the failing test.
Though there are more changes to be done, Brittany has a meeting to attend, so she ends the session by running mob done, committing, and then pushing the changes.
By running mob done command, all the changes that were on the mob/fixing-logic-issue are applied to the fixing-logic-issue branch. From here, Brittany can commit the changes and push them back to the server.
If you're looking to expand your pairing/mobbing toolkit, I recommend giving mob.sh a try. Not only is the initial investment small, but I find the tooling natural to pick up after a few tries and since it's a wrapper around Git, it reduces the amount of learning needed before getting started.
As a leader, you're always on the look out for new tools and approaches to help the team be more effective.
But what happens when you have an idea? How do you introduce it to the team and get buy-in? How do you encourage others to propose ideas as well (remember, you're job isn't to have all the ideas, but to encourage and choose the best ones).
Let's say that the idea works, what happens next? What if it failed, what do you do next? How do you share your lessons with others?
In this post, I'll walk you through my approach for running experiments with the team and how to answer these questions. Like any other advice, I've found success using this process, but you might find that you'll need to tweak or adjust for your team.
When it comes to the team, I'm a big proponent of working in the open. Not only does this reduce the amount of questions from my leader about what we're doing, it also empowers others to chime in when they see something off or the team going down the wrong path.
With this philosophy in mind, I document our experiments in the team wiki. Now, I know that we should favor people over processes, however, I have found immense value in taking the 10 minutes to document as this helps get everyone on the same page and when we look at these experiments later, we have the context behind the experiment.
To me, this no different than a scientist writing down their experiments for later reference.
As you might have guessed, I'm a big fan of using the scientific method for engineering work and especially so when it comes to experiments. As such, I capture the following info:
Seriously, if we're not taking notes, what kind of scientists are we?
Photo by Louis Reed on Unsplash
Context - Why are we doing this? What inspired the experiment or what problem are we trying to solve?
Hypothesis - What change are we proposing and what outcome are we looking for?
Implementation - How are we going to run this experiment?
Duration - How long are we going to run this experiment for?
(Optional) Immediate Failure Criteria - Is there anything that could happen during this experiment that would cause to immediately stop?
With the experiment documented, I send a meeting request the day after the experiment is scheduled to end. The goal of this meeting is to reflect on the experiment and to decide whether we should adopt the changes or to stop.
After sending this meeting, my job is to help the team implement the experiment and coach/encourage as needed. Since it's a process change, it might take a bit for the team to adjust, so showing some patience and understanding is critical here.
While we are going the through the experiment, I'm going to note any changes that I'm noticing. For example, if we're running an experiment to have asynchronous stand-ups, I'm going to take notes on how I'm feeling about the team getting updates and how they're communicating with each other.
Depending on what comes up in our one-on-ones, I might even use this as a starter question.
During the retro, the team should be doing the majority of the talking. Your role is to seed the conversation and make sure everyone gets their opinions out. I like to capture these notes on a board so that the team has clear visibility on what worked and didn't work.
Once the notes have been added to the board, it's time for the team to decide to adopt the changes or not. During this step, I remind the team that this process isn't set in stone and if we want to tweak it in a future experiment, that's normal and encouraged.
At this point, I update the experiment write-up that we did earlier with the team decision and the logic behind the decision. This provides an easy way of sharing our lessons with others.
One cool thing about leading teams is that no two teams are the same. Between the personalities, skills, company culture, and motivations, what works for one team won't work for another team (and the other way around).
Because of this, it's critical to share your results with your leader and your peers. This way, they could see what we did, what worked, what didn't work, and hopefully get inspired to run their own experiments with teams.
If the team paid a learning tax for an experiment, why wouldn't we share those results with others so that they can learn from our experiences? They might be able to make suggestions to turn a failure into a success or to ask questions about how we dealt with an issue.
The group being successful is your success, do don't hoard knowledge, share it with others!
With the write-up completed, you can start simply by sending a link to the group. A better approach would be to have a standing agenda item for your team lead meeting where leaders can talk about experiments that have been ran recently and their outcomes.
When I've worked with leaders to introduce experiments, it can be a lot to take in because this is a different way of thinking. This is especially true if leaders are not in a psychologically safe environment or if they have prior experiences that weren't successful.
I can't guarantee that you'll run experiments flawlessly, however, if you avoid these common mistakes, your odds of success will be higher.
One of the key features of the experiment is that it's only going to run for a set period of time, so that if you find that it's not working, you've not permanently impacted the team.
If you have an experiment that's going to run into perpetuity, that's not an experiment anymore, that's a process change and that shouldn't go through this workflow because experiments can be abandoned, but process changes typically can't.
At some point, you're going to get a directive from your leader that you don't agree with, but you need to commit to the idea anyway. You know the idea isn't going to go over with the team, so you think framing it as an experiment can soften the blow.
DON'T DO THIS!
Really, don't do this!
Experiments are just that, experiments. They are not a vehicle for you to make unpopular changes. If you use experiments for slipping in these types of changes, then the team will learn that experiments is code for "not great idea" and they'll stop using the process.
Remember, experiments are ideas that you and the team come up with to make things better, not directives from the top coming down.
Now, you could use an experiment to figure out a way to carry out the directive. A good leader tells you where we have to go, but not necessarily how to get there. The experiment could be to figure out how to get there, but not what the destination should be.
When getting a new team or after identifying multiple areas that a team could improve in, it's going to be tempting to want to implement multiple changes at once.
Resist the urge.
Remember, an experiment, by definition, is a process change. So the more experiments you run, the more process changes happening, which in turn puts more stress on the team to remember all the changes.
In addition to all the process changes, you might find that one experiment futzes with another experiment and you may not get clear results.
Let's say that we had two experiments going on at the same, asynchronous stand-ups and spending Tuesday afternoons in independent learning. During your one-on-ones, you get some feedback that it's a bit odd to not know what other team members are working on.
What's driving that? Is it the async stand-ups? Or is it the dedicated learning time? Could it be both? You can't be sure.
Another way to think about this is to think about debugging a program. If something's not working, do you change 5 things at once? No, you're going to change one thing, re-run, and see what happens.
Same thing for experiments.
But Cameron! This team is a hot mess and could stand to improve in so many areas, what should I do then?
Instead of running all the experiments, instead, the team should decide which experiment would have the biggest payoff and then pursue that one. Remember, you're not playing the short game, but you're in for the long haul, so you'll have the time to make those changes.