Welcome to Cameron's Coaching Corner, where we answer questions from readers about leadership, career, and software engineering.
In this post, we'll look at a question from TheRefsAlwaysWin about how to get a new engineer on their team to open up and get comfortable asking for help.
I've got a newish member to the team and they're still early in their career. They've got a good head on their shoulders, however, they tend to go down rabbit holes when problem solving and they don't speak up or ask for help.
They've asked me a few times about "how did I know ....", and a lot of the times, it's experience (I've been doing this for a few decades now).
How do I help them open up and ask more questions to the team and group?
When we talk about functions, we're not talking about a programming construct (like the function keyword), but instead we're talking about functions from mathematics.
As such, a function is a mapping from two sets such that for every element of the first set, it maps to a single element in the second set.
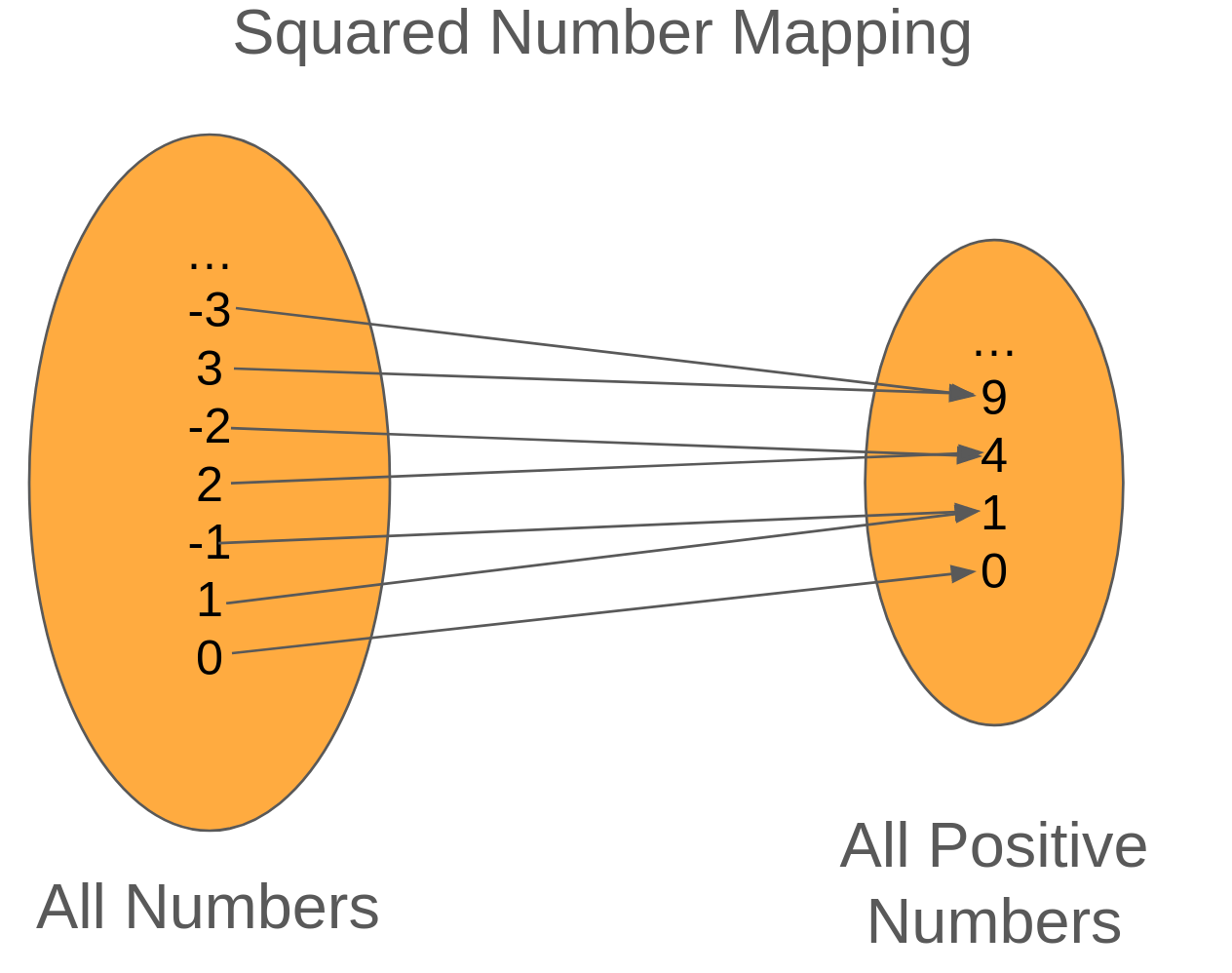
Words are cool, but pictures are better. So let's look at the mapping for the square function.
In this example, we have an arrow coming from an element on the left where it maps to an element on the right. To read this image, we have a mapping called Square that maps all possible numbers to the set of positive numbers. So -3 maps to 9 (-3-3), 2 maps to 4 (22), so on and so forth.
To check if our mapping is a function, we need to check that every element on the left is mapped to a single element on the right. If so, then we've got a function!
Sounds easy, right? Let's take a look at a mapping that isn't a function.
When working with dates, it's common to figure out how many days are in the month. Not only does this help with billable days, but it also makes sure that we don't try to send invoices on May 32nd.
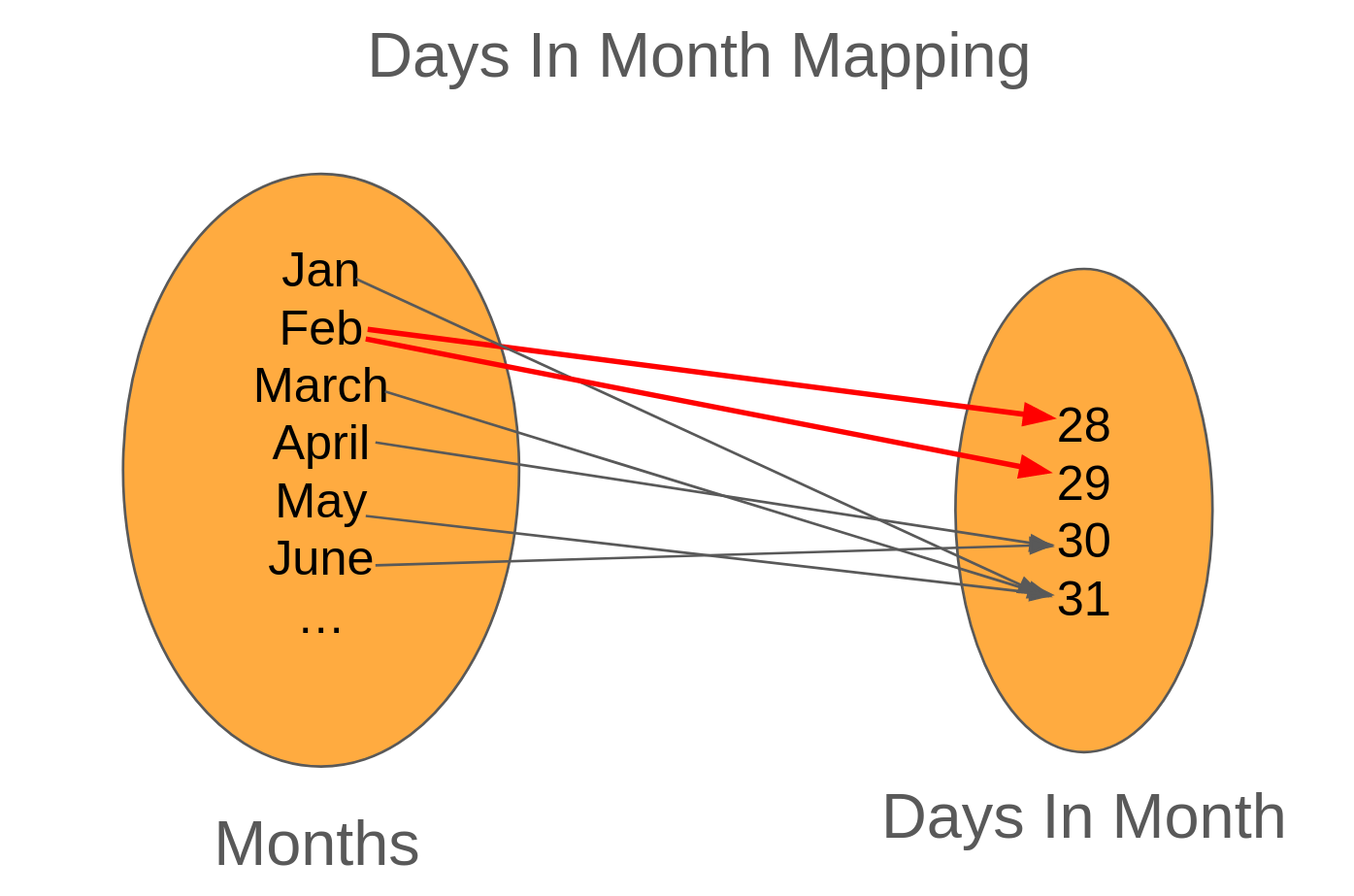
So let's take a look at a mapping from month to the number of days it has.
Looking at the mapping, we can tell that January, March, May map to 31, April and June both map to 30. But take a look at February. It's got two arrows coming out of it, one to 28 and the other to 29. Because there are two arrows coming out, this mapping isn't a function. Let's try to implement this mapping in TypeScript.
typeMonth="Jan"|"Feb"|"Mar"|"Apr"|"May"|"Jun"|"Jul"|"Aug"|"Sept"|"Oct"|"Nov"|"Dec";typeDaysInMonth=28|29|30|31;functiongetDaysInMonth(month:Month):DaysInMonth{switch(month){case"Jan":case"Mar":case"May":case"Jul":case"Oct":case"Dec":return31;case"Feb":// what should this be?case"Apr":case"Jun":case"Aug":case"Sept":case"Nov":return30;}}
We can't return 28 all the time (we'd be wrong 25% of the time) and we can't return 29 all the time (as we'd be wrong 75% of the time). So how do we know? We need to know something about the year. One approach would be to check if the current year is a leap year (algorithm).
The problem with this approach is that the determination of what to return isn't from the function's inputs, but outside state (in this case, time). So while this "works", you can get bit when you have tests that start failing when the calendar flips over because it assumed that February always had 28 days.
If we look at the type signature of isLeapYear, we can see that it takes in no inputs, but returns a boolean. How can that be possible except if it always returned a constant value? This is a clue that isLeapYear is not a function.
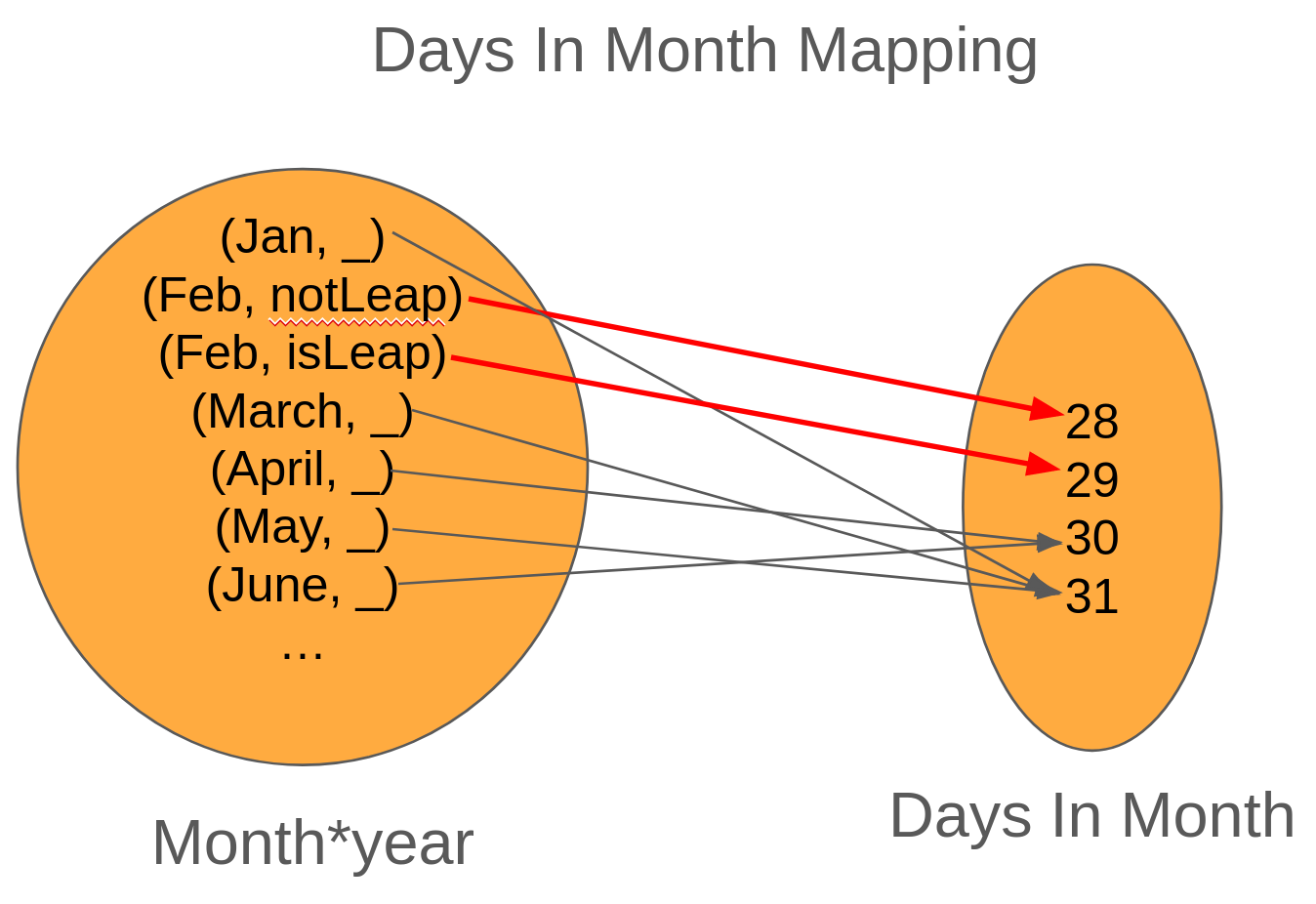
The better approach is to change our mapping to instead of taking just a month name, it takes two arguments, a monthName and year.
With this new mapping, our implementation would look like the following:
Now that we've covered what functions are and aren't, let's cover some of the reasons why we prefer functions for our logic.
First, mappings help us make sure that we've covered all our bases. We saw in the getDaysInMonth function we found a bug for when the month was February. Mappings can also be great conversation tools with non-engineers as they're intuitive to understand and to explain.
Second, functions are simple to test. Since the result is based solely on inputs, they are great candidates for unit testing and require little to no mocking to write them. I don't know about you, but I like simple test cases that help us build confidence that our application is working as intended.
Third, we can combine functions to make bigger functions using composition. At a high level, composition says that if we have two functions f and g, we can write a new function, h which takes the output of f and feeds it as the input for g.
Sounds theoretical, but let's take a look at a real example.
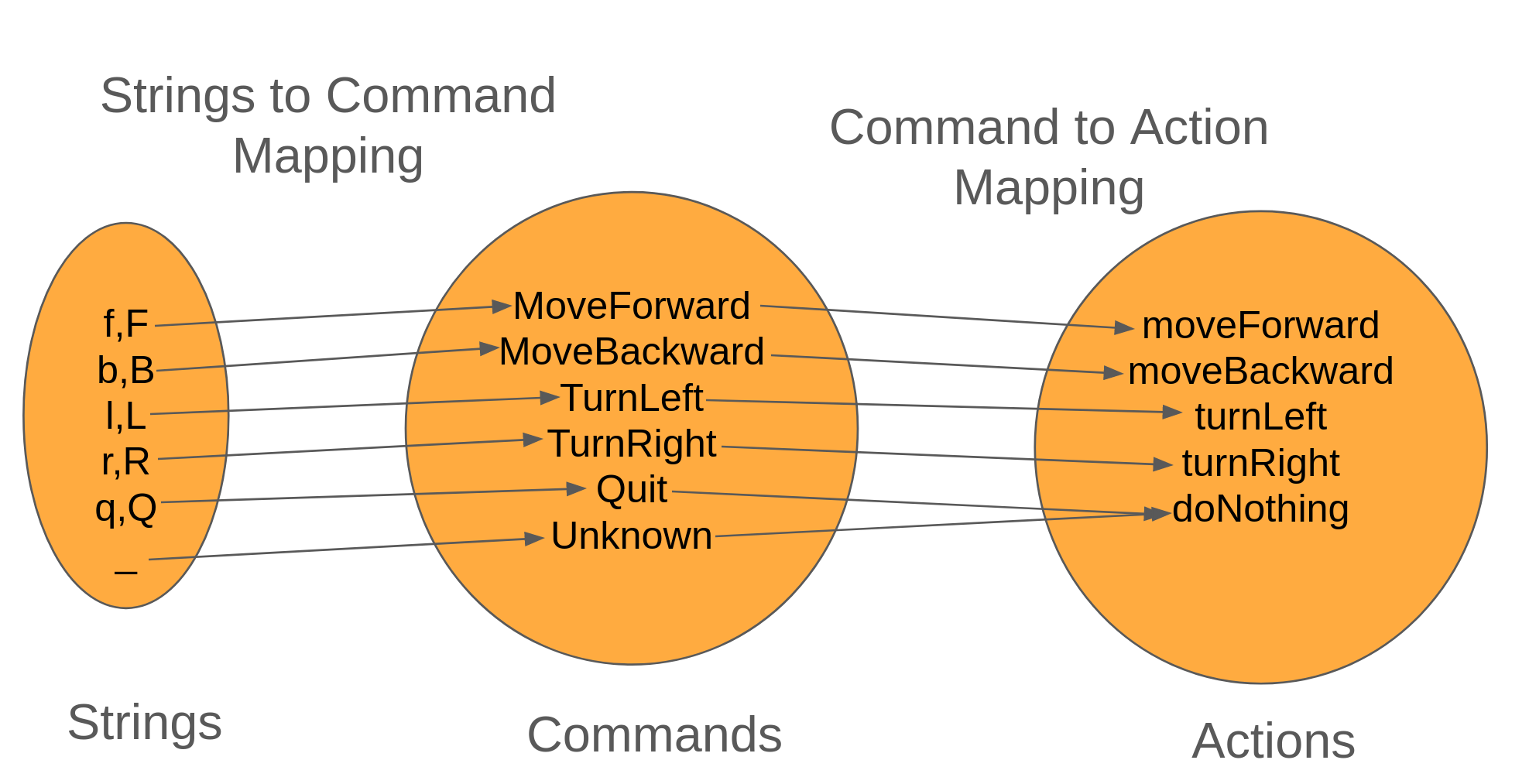
In the Mars Rover kata, we end up building a basic console application that takes the input from the user (a string) and will need to convert it to the action that the rover takes.
The annoying part is that we're iterating the list twice (once for each map call), and it'd be nice to get it down to a single iteration. This is where composition helps.
When we're running the maps back-to-back, we're accomplish the following workflow
Because each mapping is a function, we can compose the two into a new function, stringToActionConverter.
// using our f and g naming from earlier, convertString is f, convertCommand is gconststringToActionConverter=(s:string)=>convertCommandToAction(convertStringToCommand(s));letrover={x:0,y:0,direction:'North'}constaction=input.split('').map(stringToActionConverter);rover=action(rover);
Functions can greatly simplify our mental model as we don't have to keep track of state or other side effects. However, our applications typically deal with side affects (getting input from users, reading from files, interacting with databases) in order to do something useful. Because of this limitation, we strive to put all of our business rules into functions and keep the parts that interact with state as dumb as possible (that way we don't have to troubleshoot as much).
What I've found is that when working with applications, you end up with a workflow where you have input come in, gets processed, and then the result gets outputted.
// Logic to determine the 'FizzBuzziness' of a numberfunctiondetermineFizzBuzz(input:number):string{if(input%15===0)return'FizzBuzz';if(input%3===0)return'Fizz';if(input%5===0)return'Buzz';return`${input}`;}functionworkflow():void{// Input Boundaryvarprompt=require('prompt-sync')();constinput=prompt();// Business Rulesconstresult=(+input)?`${input} FizzBuzz value is ${determineFizzBuzz(+input)}`:`Invalid input`;// Output boundaryconsole.log(result);}
Now that we have a rough understanding of functions, we can start exploring what happens when things go wrong. For example, could there have been a cleaner way of implementing the business rules of our workflow?
I've recently found myself picking up C# again for a project and even though much of my knowledge applies, I recently found the following and it took me a minute to figure out what's up.
Let's say that we're working on the Mars Rover kata and we've decided to model the Rover type as a class with three fields: x, y, and direction.
My normal approach to this problem would have been the following:
publicenumDirection{North,South,East,West}publicclassRover{privateint_x;privateint_y;privateDirection_direction;publicRover(intx,inty,Directiondirection){_x=x;_y=y;_direction=Direction;}publicvoidPrint(){Console.WriteLine($"Rover is at ({_x}, {_y}) facing {_direction}");}}// Example usagevarrover=newRover(10,20,Direction.North);rover.Print();// Rover is at (10, 20) facing North
However, in the code I was working with, I saw the Rover definition as this
// note the params at the class line herepublicclassRover(intx,inty,Directiondirection){publicvoidPrint(){Console.WriteLine($"Rover is at ({x}, {y}) facing {direction}");}}// Example Usagevarrover=newRover(10,20,Direction.North);rover.Print();// Rover is at (10, 20) facing North
At first, I thought this was similar to the record syntax for holding onto data
And it turns out, that it is! This feature is known as a primary constructor and when used with classes, it gives you some flexibility on how you want to access those inputs.
For example, in our second implementation of Rover, we're directly using x, y, and direction in the Print method.
However, let's say that we didn't want to use those properties directly (or if we need to set some state based on those inputs), then we could do the following.
publicclassRover(intx,inty,Directiondirection){privatereadonlybool_isFacingRightDirection=direction==Direction.North;publicvoidPrint(){if(_isFacingRightDirection){Console.WriteLine("Rover is facing the correct direction!");}Console.WriteLine($"Rover is at ({x}, {y}) facing {direction}");}}
After playing around this for a bit, I can see how this feature would be beneficial for classes that only store their constructor arguments for later usage.
Even though Records accomplish that better, you can't attach functionality to Records, but you can with classes, so it does provide better organization from that front.
That being said, I'm not 100% sure why we needed to add the primary constructor feature to the language as this now opens up multiple ways of setting up constructors. I'm all for giving developers choices, but this seems ripe for bike shedding where teams have to decide which approach to stick with.
When modeling types, one thing to keep in mind is to not leverage primitive types for your domain. This comes up when we use a primitive type (like a string) to represent core domain concepts (like a Social Security Number or a Phone Number).
Here's an example where it can become problematic:
// Definition for CustomertypeCustomer={firstName:string,lastName:string,email:string,phoneNumber:string}// Function to send an email to customer about a new saleasyncfunctionsendEmailToCustomer(c:Customer):Promise<void>{constcontent="Look at these deals!";// Uh oh, we're trying to send an email to a phone number...awaitsendEmail(c.phoneNumber,content);}asyncfunctionsendEmail(email:string,content:string):Promise<void>{// logic to send email}
There's a bug in this code, where we're trying to send an email to a phone number. Unfortunately, this code type checks and compiles, so we have to lean on other techniques (automated testing or code reviews) to discover the bug.
Since it's better to find issues earlier in the process, we can make this a compilation error by introducing a new type for Email since not all strings should be treated equally.
One approach we can do is to create a tagged union like the following:
functionsendEmail(email:Email,content:string):Promise<void>{// logic to send email}
Now, when we get a compilation error when we try passing in a phoneNumber.
One downside to this approach is that if you want to get the value from the Email type, you need to access it's value property. This can be a bit hard to read and keep track of.
One technique to avoid this is to use destructuring to get the individual properties. This allows us to "throw away" some properties and hold onto the ones we care about. For example, let's say that we wanted only the phoneNumber from a Customer. We could get that with an assignment like the following:
constcustomer:Customer={firstName:"Cameron",lastName:"Presley",phoneNumber:"555-5555",email:{label:"Email",value:"Cameron@domain.com"}}const{phoneNumber}=customer;// phoneNumber will be "555-555"
This works fine for assignments, but it'd be nice to have this at a function level. Thankfully, we can do that like so:
// value is the property from Email, we don't have the label to deal withfunctionsendEmail({value}:Email,content:string):Promise<void>{constaddress=value;// note that we don't have to do .value here// logic to send email}
If you find yourself using domain types like this, then this is a handy tool to have in your toolbox.
As someone who enjoys leveraging technology and teaching, I'm always interested in ways to simplify the teaching process.
For example, when I'm teaching someone a new skill, I follow the "show one, do one, lead one" approach and my tool of choice for the longest time was LiveShare by Microsoft.
I think this extension is pretty slick as it allows you to have multiple collaborators, the latency is quite low, and it's built into both Visual Studio Code (VS Code) and Visual Studio.
First, participants have to be using Visual Studio or VS Code. Since there's support for VS Code, this isn't quite a blocker as it could be. However, let's say that I'm wanting to work with a team on a Java application. They're more likely to be using IntelliJ or Eclipse as their editor and I don't want someone to have to change their editor just to collaborate.
Second, there are some security considerations to be aware of.
Given the nature of LiveShare, collaborators either connect to your machine (peer-to-peer) or they go through a relay in Azure. Companies that are sensitive to where traffic is routed to won't allow the Azure relay option and given the issues with the URL creation (see next section), the peer-to-peer connection isn't much better.
To start a session, LiveShare generates a URL that the owner would share with their collaborators. As of today, there's no way to limit who can access that link. The owner has some moderator tools to block people, but there's not a way to stop anyone from joining who doesn't have the right kind of email address for example.
While pairing with a colleague, he introduced me to an alternative tool, mob.sh
At first, I was a bit skeptical of this tooling as I enjoyed the ease of use that I got with LiveShare. However, after a few sessions, I find that this tool solves the problems that I was using LiveShare for just as good, if not better.
At a high level, mob.sh is a command line tool that is a wrapper around basic git commands.
Because of this design choice, it doesn't matter what editor that a participant has, as long as the code under question is under git source control, the tooling works.
Let's explore how a pair, Adam and Brittany, would use this tool for work.
gitswitch-cfixing-logic-issue
mobstart--create
# --create is needed because fixing-logic issue is not on the server yet
Under the hood, mob.sh has created a new branch off of fixing-logic-issue called mob/fixing-logic-issue. While Adam is making changes, they're going to occur on the mob/fixing-logic-issue.
Because the pair is working remotely, Adam shares his screen so that they're on the same page.
While on this branch, Adam writes a failing unit test that exposes the logic issue that he's running into. From here he signals that Brittany is up by running mob next
By running this command, mob.sh adds and commits all the changes made on this branch and pushes them up to the server. Once this command completes, it's Brittany's turn to lead.
Once Brittany see's the mob next command complete, she checks out the fixing-logic-issue branch and picks up the next portion of the work by running mob start
gitpull# To get fixing-logic-issue branchgitswitchfixing-logic-issue
mobstart
Because she was on the fixing-logic-issue branch, mob.sh was able to see that there was a mob/fixing-logic-issue branch already, so that branch is checked out.
Based on the test, Brittany shows Adam where the failure is occurring and they write up a fix that passes the failing test.
Though there are more changes to be done, Brittany has a meeting to attend, so she ends the session by running mob done, committing, and then pushing the changes.
By running mob done command, all the changes that were on the mob/fixing-logic-issue are applied to the fixing-logic-issue branch. From here, Brittany can commit the changes and push them back to the server.
If you're looking to expand your pairing/mobbing toolkit, I recommend giving mob.sh a try. Not only is the initial investment small, but I find the tooling natural to pick up after a few tries and since it's a wrapper around Git, it reduces the amount of learning needed before getting started.
As a leader, you're always on the look out for new tools and approaches to help the team be more effective.
But what happens when you have an idea? How do you introduce it to the team and get buy-in? How do you encourage others to propose ideas as well (remember, you're job isn't to have all the ideas, but to encourage and choose the best ones).
Let's say that the idea works, what happens next? What if it failed, what do you do next? How do you share your lessons with others?
In this post, I'll walk you through my approach for running experiments with the team and how to answer these questions. Like any other advice, I've found success using this process, but you might find that you'll need to tweak or adjust for your team.
When it comes to the team, I'm a big proponent of working in the open. Not only does this reduce the amount of questions from my leader about what we're doing, it also empowers others to chime in when they see something off or the team going down the wrong path.
With this philosophy in mind, I document our experiments in the team wiki. Now, I know that we should favor people over processes, however, I have found immense value in taking the 10 minutes to document as this helps get everyone on the same page and when we look at these experiments later, we have the context behind the experiment.
To me, this no different than a scientist writing down their experiments for later reference.
As you might have guessed, I'm a big fan of using the scientific method for engineering work and especially so when it comes to experiments. As such, I capture the following info:
Seriously, if we're not taking notes, what kind of scientists are we?
Photo by Louis Reed on Unsplash
Context - Why are we doing this? What inspired the experiment or what problem are we trying to solve?
Hypothesis - What change are we proposing and what outcome are we looking for?
Implementation - How are we going to run this experiment?
Duration - How long are we going to run this experiment for?
(Optional) Immediate Failure Criteria - Is there anything that could happen during this experiment that would cause to immediately stop?
With the experiment documented, I send a meeting request the day after the experiment is scheduled to end. The goal of this meeting is to reflect on the experiment and to decide whether we should adopt the changes or to stop.
After sending this meeting, my job is to help the team implement the experiment and coach/encourage as needed. Since it's a process change, it might take a bit for the team to adjust, so showing some patience and understanding is critical here.
While we are going the through the experiment, I'm going to note any changes that I'm noticing. For example, if we're running an experiment to have asynchronous stand-ups, I'm going to take notes on how I'm feeling about the team getting updates and how they're communicating with each other.
Depending on what comes up in our one-on-ones, I might even use this as a starter question.
During the retro, the team should be doing the majority of the talking. Your role is to seed the conversation and make sure everyone gets their opinions out. I like to capture these notes on a board so that the team has clear visibility on what worked and didn't work.
Once the notes have been added to the board, it's time for the team to decide to adopt the changes or not. During this step, I remind the team that this process isn't set in stone and if we want to tweak it in a future experiment, that's normal and encouraged.
At this point, I update the experiment write-up that we did earlier with the team decision and the logic behind the decision. This provides an easy way of sharing our lessons with others.
One cool thing about leading teams is that no two teams are the same. Between the personalities, skills, company culture, and motivations, what works for one team won't work for another team (and the other way around).
Because of this, it's critical to share your results with your leader and your peers. This way, they could see what we did, what worked, what didn't work, and hopefully get inspired to run their own experiments with teams.
If the team paid a learning tax for an experiment, why wouldn't we share those results with others so that they can learn from our experiences? They might be able to make suggestions to turn a failure into a success or to ask questions about how we dealt with an issue.
The group being successful is your success, do don't hoard knowledge, share it with others!
With the write-up completed, you can start simply by sending a link to the group. A better approach would be to have a standing agenda item for your team lead meeting where leaders can talk about experiments that have been ran recently and their outcomes.
When I've worked with leaders to introduce experiments, it can be a lot to take in because this is a different way of thinking. This is especially true if leaders are not in a psychologically safe environment or if they have prior experiences that weren't successful.
I can't guarantee that you'll run experiments flawlessly, however, if you avoid these common mistakes, your odds of success will be higher.
One of the key features of the experiment is that it's only going to run for a set period of time, so that if you find that it's not working, you've not permanently impacted the team.
If you have an experiment that's going to run into perpetuity, that's not an experiment anymore, that's a process change and that shouldn't go through this workflow because experiments can be abandoned, but process changes typically can't.
At some point, you're going to get a directive from your leader that you don't agree with, but you need to commit to the idea anyway. You know the idea isn't going to go over with the team, so you think framing it as an experiment can soften the blow.
DON'T DO THIS!
Really, don't do this!
Experiments are just that, experiments. They are not a vehicle for you to make unpopular changes. If you use experiments for slipping in these types of changes, then the team will learn that experiments is code for "not great idea" and they'll stop using the process.
Remember, experiments are ideas that you and the team come up with to make things better, not directives from the top coming down.
Now, you could use an experiment to figure out a way to carry out the directive. A good leader tells you where we have to go, but not necessarily how to get there. The experiment could be to figure out how to get there, but not what the destination should be.
When getting a new team or after identifying multiple areas that a team could improve in, it's going to be tempting to want to implement multiple changes at once.
Resist the urge.
Remember, an experiment, by definition, is a process change. So the more experiments you run, the more process changes happening, which in turn puts more stress on the team to remember all the changes.
In addition to all the process changes, you might find that one experiment futzes with another experiment and you may not get clear results.
Let's say that we had two experiments going on at the same, asynchronous stand-ups and spending Tuesday afternoons in independent learning. During your one-on-ones, you get some feedback that it's a bit odd to not know what other team members are working on.
What's driving that? Is it the async stand-ups? Or is it the dedicated learning time? Could it be both? You can't be sure.
Another way to think about this is to think about debugging a program. If something's not working, do you change 5 things at once? No, you're going to change one thing, re-run, and see what happens.
Same thing for experiments.
But Cameron! This team is a hot mess and could stand to improve in so many areas, what should I do then?
Instead of running all the experiments, instead, the team should decide which experiment would have the biggest payoff and then pursue that one. Remember, you're not playing the short game, but you're in for the long haul, so you'll have the time to make those changes.
Most of my blog posts cover process improvements, leadership advice, and new (to me) technologies. In this post, I wanted to shift a bit and cover some of the fun troubleshooting problems that I run into from time to time.
At a high level, the team had a need to process messages coming from a message queue, parse the data, and then insert into a DynamoDB table. At a high level, here's what the architecture looked like:
graph LR
Queue[Message Queue] --> Lambda[Lambda]
Lambda --> Process[Process?]
Process --> |Failed| DLQ[Dead Letter Queue]
Process --> |Success| DB[DynamoDB Table]
The business workflow is that a batch job was running overnight that would send messages to various queues (including this one). The team knew that we would receive about 100K messages, but had plenty of time to process them as this data was not needed for real-time.
For the first night, everything worked as intended. However, for the second night, the team saw that only some of the messages made it to their DynamoDB table. A non-trivial number of them errored out with a message of Error: connect EMFIL <IP ADDRESS>.
I don't know about you, but I had never seen EMFIL as an error before and the logs weren't very helpful on what was going on.
Doing some digging, we found this GitHub Issue where someone has ran into a similar problem.
Digging through the comment chain, we found this comment, stating that you could run into this problem if you were exhausting the connection pool to DynamoDB.
Ah, now that's an idea! Even though I hadn't seen that error before, I know that if an application isn't cleaning up their connections properly, then the server can't accept new ones and that would fail the application. With almost 100K messages coming through and the large amount of failures, I could absolutely see how that might be the issue.
exportconsthandler=(event)=>{// logic to parse eventconstdbClient=DynamoDbDocumentClient.from(newDynamoDBClient());// logic to insert event}
Aha! This code implies that for every execution of the lambda, it would attempt to create a new connection.
But Cameron, hold up. Yes, it will create the connection every time the lambda executes, but once the lambda is done, the connection will get cleaned up, so will it really try to spin up 100K connections?
You're right, when the lambda goes out of scope, the connection will get cleaned up.
But don't forget, it'll take the target server (DynamoDB) some time to tidy up. The problem is that since we were slamming 100K messages in rapid succession, DynamoDB didn't have enough time to clean up the connection before another connection was requested. And that was the problem.
Now that we have an idea on what the problem could be, time to fix it. In this case, the change is straightforward (though the reasoning might not be.)
constdbClient=DynamoDbDocumentClient.from(newDynamoDBClient());exportconsthandler=(event)=>{// logic to parse event// logic to insert event}
Wait, wait. How does this solve the problem? You're still going to be executing this code for every message, so won't you have the same issue?
Now that's a great question! Something that the team learned is that when a Lambda gets spun-up, there's a context that's created that hosts the external dependencies. When a lambda execution finishes, the context is maintained by AWS for a certain amount of time to be reused in case the lambda is invoked again. This saves on the init/start-up times.
Because of the shared context, this allows us to essentially pool the connections and drastically reduce the amount of connections needed.
This same advice is given in the best practices documentation for lambdas.
After making the code change and redeploying, we were able to confirm that everything was working again with no issues.
Even though the problem was new to us, this was a great opportunity to learn more about how Lambdas work under the hood, understand more about execution context, and a bit of dive into troubleshooting unknown errors for the team.
When writing software, it's difficult (if not impossible) to write everything from scratch. We're either using a framework or various third-party libraries to make our code work.
On one hand, this is a major win for the community because we're not all having to solve the same problem over and over again. Could you imagine having to implement your own authentication framework (on second thought...)
However, this power comes at a cost. These libraries aren't free as in beer, but more like puppies. So if we're going to take in the library, then we need to make sure that our dependencies are up-to-date with the latest and greatest. There are new features, bug fixes, and security patches occurring all the time and the longer we let a library drift, the more painful it can be to upgrade.
If the library is leveraging semantic versioning, then we can take a guess on the likelihood of a breaking change base on which number (Major.Minor.Maintenance) has changed.
Major - We've made a breaking change that's not backward compatible. Your code may not work anymore.
Minor - We've added added new features that you might be interested in or made other changes that are backwards compatible.
Maintenance - We've fixed some bugs, sorry about that!
For libraries that have known vulnerabilities, you can leverage tools like GitHub's Dependabot to auto-create pull requests that will upgrade those dependencies for you. Even though the tool might be "noisy", this is a great way to take an active role in keeping libraries up to date.
However, this approach only works for vulnerabilities, what about libraries that are just out-of-date? There's a cost/benefit of upgrading where the longer you go between the upgrades, the riskier the upgrade will be.
In the JavaScript world, we know that dependencies are listed in the package.json file with minimum versions and the package-lock.json file states the exact versions to use.
I was working with one of my colleagues the other day and he referred me to a library called LibYear that will check your package.json and lock file to determine how much "drift" that you have between your dependencies.
Under the hood, it's combining the npm outdated and npm view <package> commands to determine the drift.
What I like about this tool is that you can use this as a part of a "software health" report for your codebase.
As engineers, we get pressure to ship features and hit delivery dates, but it's our responsibility to make sure that our codebase is in good shape (however we defined that term). I think this library is a good way for us to capture a data point about software health which then allows the team to make a decision on whether we should update our libraries now (or defer).
The nice thing about the LibYear package is that it lends itself to be ran in a pipeline and then you could take those results and post them somewhere. For example, maybe you could write your own automation bot that could post the stats in your Slack or Teams chat.
As engineers, we love solving problems and digging into the details. I know that I feel a particular sense of joy when shipping a system to production for the first time.
However, once a system goes into production, it's going to fail. That's not a knock on engineering, that's a fact of our industry. We cannot build a system with 100% uptime, no matter how much we plan ahead or think about.
When this happens, our job is to fix the issue and bring the systems back up.
A common mistake that I see teams make is that they'll fix the problem, but never dig into the why it happened. Fast forward three months, and the team will run into the same problem, making the same mistakes. I'm always surprised when teams don't share their knowledge because if you've paid the tax of learning from the first outage, why would you pay the same tax to learn the lesson again?
This is where having a postmortem meeting comes into play. Borrowing from medicine, a postmortem is performed when the team gets together to analyze the outage and what could have been done differently to prevent it from happening. Other industries have similar mechanisms (for example, professional athletes review their games to learn where they made mistakes so that they can train differently).
One of the key concepts of the postmortem is that the goal isn't to assign blame, but to understand what happened and why. People aren't perfect and it's not reasonable for them to be. This concept is so fundamental that another term you might here for a postmortem is a blameless incident report (BIR).
Are you interesting learning how to run your own BIR process? Drop me a line and if there's enough interest, I'll write a follow-up post!
Every company has their own process when they have an outage, but health process should be able to answer these five questions at a minimum.
What stopped working?
Why did it stop working?
How did we fix it?
What led to the system breaking?
What are we doing to prevent this issue from happening in the future?
Organizations may have additional questions for their process, for example
What was the impact? (X customers were impacted for Y minutes)
How was this discovered? (Was it user reported, support found it, our monitoring tools paged on-call)
You can always make a process more complicated, but it's hard to simplify a process, so my recommendation is start with the 5 questions and then expand as your team evolves and matures.
For there to be an outage, something had to stop working, right? So what was it? It's okay/normal to be a bit technical here, however, don't forget that this outage caused an impact to our users, so we should strive to explain the outage in those terms.
Another way to think about this is "What stopped working and what impact did it have for our users?"
Here's a not-great answer to the question
The Data Sync Java container stopped working.
While this does capture what stopped working, the details are quite vague. For example, did it not start? Did it start crashing? Was it the whole process that failed or only one part?
In addition, there's not a clear delineation of what the user impact was. For example, could users not log into the application at all? Were there certain parts of the application that stopped working?
We can improve this by including a bit more details in what specifically stopped working.
The Data Sync process was failing to connect to the UserHistory database.
Ah, okay, now we know that the sync process wasn't able to connect to a specific database and we can start getting a sense of why that would be a big deal. We're still not including the user impact, so let's add that bit of detail in.
The Data Sync process was failing to connect to the UserHistory database. As such, when users logged into their account, they could not see the latest transactions for their account.
Much better, now I know that our users couldn't see recent transactions and it was something to do with the Data Sync process.
As a side benefit, if I'm a new engineer to this codebase or team, I know know more about the architecture and that this process is involved for when users start transactions.
At some point, the system was working and if it's no longer working, something had to have happened, so what was it? Was there a code deployment to production? Did a feature flag get toggled that had an adverse effect? What about infrastructure changes like DNS entries or firewall?
This is a key critical step because if we don't know why it stopped working, then we don't have a good spot to start when we start diving into the circumstances behind what led to the outage.
This doesn't have to be a page worth of technical deep dive, a couple of sentences can suffice here. In our outage, the issue was due to a port being blocked by the firewall (where it wasn't before).
There was an infrastructure change for the database that blocked port 1433, which is the default port for the database. Because of this change, no application was able to successfully connect to the database.
If you've gotten to the point of writing the BIR, then you've fixed the issue and the system is up and running again, right? So what did you do to fix the issue? Did you rollback the deployment? Disable a feature flag? Burn down the application, change your name and get a new job? This is a cool part of the BIR because you're leveling up others that if they run into a similar issue, here's how you were able to get back up and running.
In our example, we were able to unblock the port, so we can answer this question with:
Once we realized that port 1433 was being blocked by the firewall, we worked with the Infrastructure team to unblock the port. Once that change was completed, the Data Sync service was able to start syncing data to the UserHistory database.
This is where the meat of the conversation should take place. In a healthy organization, we assume that people are wanting to do the right thing (if not, you have a much bigger problem that BIRs). So we've got to figure out how did we get here, what were the motivations and why did we do the things that we did?
One common approach is 5 Whys, made popular by the Toyota Production System. The idea is that we keep digging into why something happened and not stop at symptoms.
An example 5 Whys breakdown for this outage could be the following:
-Why did the Data Sync service started failing to connect to the UserHistory database?
-Because the port that the Data Sync service was communicating with got blocked
-Why did the port become blocked?
-One of our security initiatives is to block default ports to lessen the changes of someone gaining access to our systems
-Why is this an initiative?
-Our current firewall solution doesn't support a way to have an _allowList_ of dynamic IP addresses. Since most vulnerability tools scan a network, they'll typically use default ports to see if there's a service running there and if so, try to compromise it.
-Why doesn't our current firewall solution have support for dynamic IP addresses?
-Why did we not see this issue in the lower environments?
-The lower environments are not configured the same as our production environment
-Why are these environments different?
-Given that lowers receive less traffic than production, we have multiple databases installed on the same server, none of which are on the default port. By doing this, we're saving money on infrastructure costs.
-Why did the team not realize that the lowers are configured differently?
-The Data Sync process is an older part of our application that most of the team doesn't have knowledge of.
-Why did our monitoring tools not catch the issue after deployment?
-For the Data Sync process, we currently only have a health check, which only checks to see if the app is up, it doesn't check that it has line-of-sight to all its dependencies.
-Why doesn't the health check include dependency checking?
-Health checks are used to tell our cloud infrastructure to restart a service. Since restarting the service wouldn't have resolved the problem, that's why we don't have it included in the checks
-Why don't we have other checks?
-The Data Sync process predates our existing monitoring solutions and has been stable, so the work was never prioritized.
As you can see, this approach brings up lots of questions, including the motivation behind the work and why the team was doing it anyway. It is possible
The system is going to have an outage, that's not up for debate. However, it would be foolish to have an outage and not do anything to prevent it from happening in the future. If we already paid the learning tax once, let's not pay it again for the same issue.
This should be a concrete list of action items that the team takes ownership of. In some cases, it's work that they can do to prevent the issue going forward. In some cases, it could be working with others to help them fix things in their process.
In our hypothetical outage, we could have the following action items
Add Additional Monitoring for the Data Sync process
Work with Security to determine approach for securing our database instance
In this post, we covered the 5 main questions to answer for a BIR and what good responses look like. In this section, I wanted to go over an example BIR for the database issue that we've been exploring. As you'll see, it's not a verbose document, however, it does capture the main points and this is easily consumable for other teams to learn from our mistakes.
# Title: Users Unable To See Latest Transactions## What Stopped Working?The Data Sync process stopped being able to connect to the UserHistory Database. Because of this failure, when users logged into their account to see transactions, they were not able to see any new transactions.
## Why Did It Stop Working?A change was made to the database infrastructure to block port 1433. This is the default port for a SQL Server database so when it was blocked, no application was able to communicate with the database.
## How Did We Fix It?The firewall port change was reverted.
## What Led to the System Breaking?To improve our security posture, we wanted to block default ports to our systems so that if someone was to gain access, they couldn't "guess" into the connection for the database.
When making these firewall changes, we start in the lower environments so that if there is a problem, we impact dev or staging and not production.
Unknown to the team, in the lower environments, we have multiple databases installed on a server, none of which are on port 1433. Because of this, we had false confidence that our changes were safe to deploy forward.
In production, each database has their own server, running on port 1433.
## What Are We Doing To Prevent Issues In The Future?-**Check the environment differences** - Before making infrastructure changes, we're going to check what the differences are in our lower environments vs production.
-**Create architecture diagram** - Since one of the main issues is that the team didn't understand the architecture of the Data Sync process, we're going to create an architecture diagram that covers the flow of the service.
-**Create environment diagram** - To better understand our system, we're going to create an environment diagram that covers the databases at play and how the Data Sync process communicates.
-**Work with Security on Approaches for Securing Database** - We'll work with the Security team to either setup a way to have dynamic IPs work with our firewall technology or to change our Data Sync process to have a static IP.
In a previous post, we cover on how using union types in TypeScript is a great approach for domain modeling because it limits the possible values that a type can have.
For example, let's say that we're modeling a card game with a standard deck of playing cards. We could model the domain as such.
This code works, however, I don't like the fact that I had to formally list the option for both Rank and Suite as this means that I have two different representtions for Rank and Suite, which implies tthat if we needed to add a new Rank or Suite, then we'd need to add it in two places (a violation of DRY).
Doing some digging, I found this StackOverflow post that gave a different way of defining our Rank and Suite types. Let's try that new definition.
In this above code, we're saying that ranks cannot change (either by assignment or by operations like push). With that definition, we can say that Rank is some entry in the ranks array. Similar approach for our suites array and Suite type.
I prefer this approach much more because we have our ranks and suites defined in one place and our code reads cleaner as this says Here are the possible ranks and Rank can only be one of those choices.
The main limitation is that it only works for "enum" style unions. Let's change example and say that we want to model a series of shapes with the following.
To use the same trick, we would need to have an array of constant values. However, we can't have a constant value for any of the Shapes because there are an infinite number of valid Circles, Squares, and Rectangles.